
git resetも怖くない!cat-fileでGitの内部構造(ブロブ・ツリー・コミット)を完全理解
git commit
このシンプルなコマンドを叩いた瞬間、Gitの裏側で一体何が起きているか、想像したことはありますか?
Gitのコマンドは、ユーザーが日常的に使う高レベルな「Porcelain(磁器)」コマンドと、Gitの内部を直接操作する低レベルな「Plumbing(配管)」コマンドに分かれています。
「
git pullしたら大量のコンフリクトが…、焦って解消していたら、昨日書いたはずのコードが消えてしまった…」
「git reset --hardで戻れると聞いたけど、どのコミットに戻ればいいか分からず、結局何もできなかった…」
かつて私もそんな「Git怖い」病で冷や汗をかいた経験をしました。(I broke into a cold sweat after those git mistakes.) しかし、Gitの「配管」の仕組みを学んだことで、そうした恐怖から解放されたのです!
この記事を読めば、普段は意識しないPlumbingコマンド git cat-file を使い、Gitの心臓部である「オブジェクトデータベース」を探検できます。そして、トラブルにも自信を持って対処できる、Gitを自在に操るエンジニアへと成長しましょう。
この記事の対象読者
- Gitの基本的なコマンド(
add,commit)は使えるけれど、その裏側の仕組みに自信がない方 resetやrebaseといったコマンドを使うのが少し怖いと感じているジュニアエンジニア- Gitの「なぜ?」を理解し、トラブルシューティング能力を高めたいと考えているすべての開発者
目次
- 探検の準備:リポジトリの裏側を覗く装備を整えよう
- コミットの設計図:インデックス(ステージングエリア)とは?
- Gitの心臓部を探検!Plumbingコマンドで辿る3つのオブジェクト
- なぜGitはこの構造なのか?スナップショットの思想
- 歴史を書き換えても怖くない!Reflogと孤児オブジェクトの探検
- よくある質問(FAQ)
- 参考資料
- まとめ
探検の準備:リポジトリの裏側を覗く装備を整えよう
Gitの内部を探検するために、特別なツールは必要ありません。必要なのは、普段あなたが使っているGit自身です。
今回は、Gitがファイルやコミットをどのように管理しているかを直接覗き見ることができる git cat-file というPlumbingコマンドを主に使います。
まずは、探検の舞台となる小さなリポジトリを準備しましょう。以下のコマンドを実行して、準備を行ってください。
$ mkdir git-exploration
$ cd git-exploration
$ git init
$ echo "Hello, Git World!" > README.mdこれで準備は完了です。.git というディレクトリの中に、これから私たちが探検するGitの宇宙が広がっています。
コミットの設計図:インデックス(ステージングエリア)とは?
コミットを探検する前に、その設計図となる非常に重要な領域、「インデックス(ステージングエリア)」について理解しましょう。
git add コマンドを実行したとき、ファイルはどこへ行くのでしょうか? それは、このインデックスと呼ばれる場所です。インデックスは、「次のコミットに含める予定の変更リスト」を保持する、Gitリポジトリ内の特別なファイル(.git/index)です。
作業ディレクトリ、インデックス、そしてリポジトリ(オブジェクトデータベース)の関係は以下のようになります。
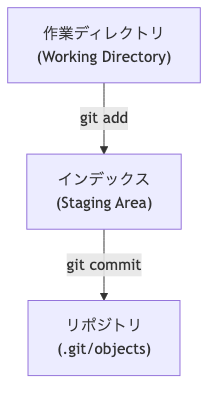
git add は、作業ディレクトリからインデックスへ変更を登録する操作です。そして git commit は、そのインデックスに登録された内容だけを元に、新しいコミット(スナップショット)を作成します。
git ls-files --stage というPlumbingコマンドを使うと、インデックスの現在の中身を覗き見ることができます。
$ git add README.md
$ git ls-files --stage
#=> 100644 557db03de997c86a4a028e1ebd3a1ceb225be238 0 README.md左から順に、ファイルモード、ファイルの中身のハッシュ値(ブロブオブジェクトのID)、ステージ番号、ファイル名が表示されています。git add を実行した時点で、Gitは README.md の中身からブロブオブジェクトを作成(または再利用)し、その情報をインデックスに記録しているのです。
この「インデックス」というワンクッションがあるおかげで、私たちは作業ディレクトリ内の変更の一部だけを選んでコミットすることができるのです。
Gitの心臓部を探検!Plumbingコマンドで辿る3つのオブジェクト
インデックスを使ってコミットの準備ができました。いよいよ git commit を実行し、Gitの心臓部であるオブジェクトデータベースを探検しましょう。
$ git commit -m "First commit: Add README.md"Gitの内部は、実は非常にシンプルなキーバリュー型のデータベースです。
すべてのデータは「オブジェクト」として、.git/objects ディレクトリに格納されています。
キーバリュー型データベースとは?
これは、辞書のように「キー」と「バリュー」のペアでデータを保存する、非常に単純な仕組みです。
- キー (Key): データを見つけるための一意のIDです。Gitでは、オブジェクトの中身から計算されるハッシュ値がキーになります。歴史的にSHA-1というアルゴリズムが使われてきましたが、現在ではセキュリティ上の理由から、より安全なSHA-256への移行が進んでいます。
- バリュー (Value): 保存したいデータ本体です。Gitでは、ブロブ・ツリー・コミットという3種類のオブジェクトの中身がバリューになります。
つまり、Gitは a1b2c3d... (ハッシュ値) というキーで、commit ... (コミットオブジェクトの中身) というバリューを管理しているのです。
3つのオブジェクトの役割
Gitのデータベースに格納されるオブジェクトは、主に以下の3種類です。それぞれの役割を、図書館の比喩で理解しましょう。
- ブロブ (Blob) – ファイルの中身そのものである本
- ファイルの中身(データ)だけを純粋に保持します。
- ファイル名やタイムスタンプといったメタ情報は含みません。そのため、中身が同じであれば、ファイル名が違っても同じブロブオブジェクトが再利用されます。
- ツリー (Tree) – ディレクトリ構造を示す棚の配置図
- 特定のディレクトリの中身を記録します。
- ファイル名やディレクトリ名の一覧と、それに対応するブロブオブジェクト(ファイルの場合)や、別のツリーオブジェクト(サブディレクトリの場合)のハッシュ値を保持しています。
- コミット (Commit) – 「いつ、誰が、何を」を記録した日報
- プロジェクトの特定の時点での「セーブポイント」です。
- 「いつ(タイムスタンプ)」「誰が(作者情報)」「なぜ(コミットメッセージ)」といった情報と共に、プロジェクト全体のファイル構成を記録した1つのツリーオブジェクトを指し示します。
これらのオブジェクトは、以下のように連携してプロジェクトの「スナップショット」を表現しています。コミットを辿れば、その時点でのすべてのファイル構成と内容を復元できるのです。
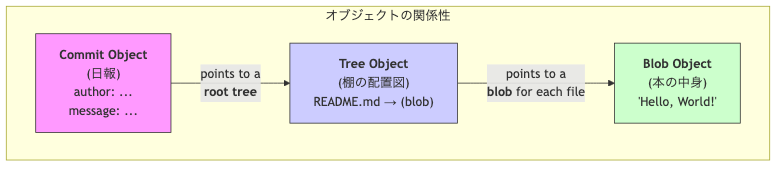
これから、「First commit」を起点に、オブジェクトたちがどのようにつながっているかを辿っていきましょう。
ステップ1: 「コミット」オブジェクトを追う – すべての歴史はここから
コミットは、あなたの「セーブポイント」の実体です。git rev-parse HEAD を使うことで、最新のコミットIDを簡単に取得できます。
$ LATEST_COMMIT=$(git rev-parse HEAD)
$ echo "Latest commit is: $LATEST_COMMIT"
# コミットの種類と中身を確認 (Plumbingコマンドを使用)
$ git cat-file -t $LATEST_COMMIT
#=> commit
$ git cat-file -p $LATEST_COMMIT
#=> tree 4b825d... (あなたの環境ではハッシュ値が異なります)
#=> author Your Name <your.email@example.com> 1678886400 +0900
#=> committer Your Name <your.email@example.com> 1678886400 +0900
#=>
#=> First commit: Add README.mdこれがコミットオブジェクトの正体です! tree という行で、プロジェクト全体のファイル構成を記録したツリーオブジェクトを指し示しているのがわかります。
ステップ2: 「ツリー」オブジェクトを辿る – プロジェクトの地図を広げる
先ほどのコミットオブジェクトが指していた tree のハッシュ値を使い、ツリーの中身も覗いてみましょう。
# 先ほどのコミットが指すツリーIDを変数に格納
$ TREE_ID=$(git rev-parse $LATEST_COMMIT^{tree})
$ echo "Tree ID is: $TREE_ID"
# ツリーの中身を確認
$ git cat-file -p $TREE_ID
#=> 100644 blob 557db03de997c86a4a028e1ebd3a1ceb225be238 README.mdツリーオブジェクトには、そのディレクトリに含まれるファイルやサブディレクトリの一覧が記録されています。ここから、README.md というファイルの実体が 557db03... というIDを持つ「ブロブ」オブジェクトであることが分かりました。
ステップ3: 「ブロブ」オブジェクトに到達する – ファイル本体とのご対面
ついに最後のオブジェクトです。「ブロブ (Blob)」は、ファイルの中身そのものを保持しています。
# ツリーからブロブのIDを特定して中身を見る
$ BLOB_ID=$(git rev-parse $TREE_ID:README.md)
$ echo "Blob ID is: $BLOB_ID"
$ git cat-file -p $BLOB_ID
#=> Hello, Git World!見覚えのある内容が表示されましたね!重要なのは、ブロブはファイル名を含まない、純粋なデータの中身だけを保持している点です。
そしてこのオブジェクトは、.git/objectsディレクトリの中に、ハッシュ値の最初の2文字をディレクトリ名、残りの38文字をファイル名として、zlibという形式で圧縮されて保存されます。まさにGitの裏側(Plumbing)です!
【ここで一息☕️クイズタイム!】
もし、README.mdのファイル名は変えずに、中身のテキストをHello, Awesome World!に書き換えてコミットした場合、新しい「ブロブ」オブジェクトは作成されるでしょうか?
- はい、作成されます。
- いいえ、作成されません。
答え
答え:1. はい、作成されます。
ブロブはファイルの中身そのものです。中身が1文字でも変われば、全く新しいハッシュ値を持つ新しいブロブオブジェクトが作成されます。これがGitのデータの完全性を保証する仕組みです!
なぜGitはこの構造なのか?スナップショットの思想
探検お疲れ様でした!
私たちは、コミットからツリー、ブロブへと参照を辿ることで、プロジェクトの特定の瞬間(スナップショット)を確認できることを見てきました。
他の多くのバージョン管理システムが、最初のバージョンからの「差分」を記録していくのに対し、Gitはコミットごとにプロジェクト全体の「スナップショット」を記録します。
スナップショットと差分管理の違い
以下の図は、スナップショットの概念を示しています。コミットごとに、その時点でのプロジェクト全体のファイル構成(ツリー)への参照を持っています。重要なのは、変更がなかったファイル(File A)は、異なるコミット間でも同じデータ(ブロブ)を再利用している点です。これにより、スナップショット方式でありながら、ストレージは非常に効率的に使われます。
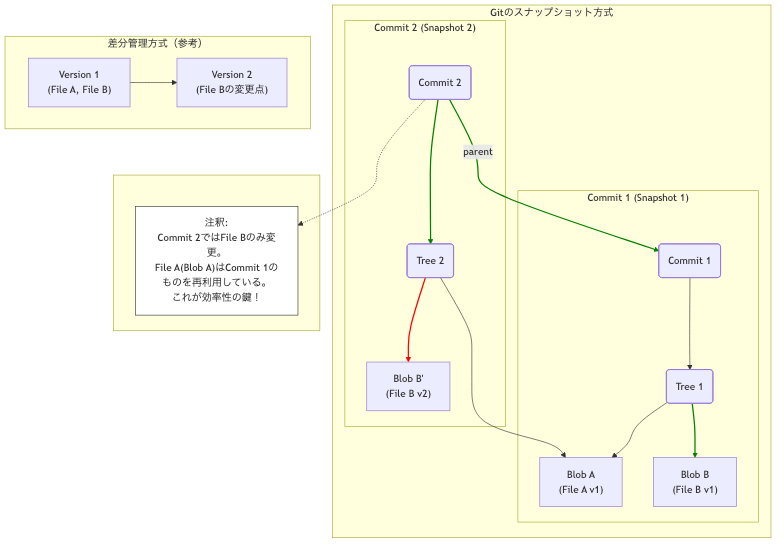
この「スナップショット」という設計思想が、Gitに高速性、堅牢性、そして分散開発との高い親和性をもたらしているのです。
さらに、各コミットは親コミットのハッシュ値を持つことで、過去の歴史が一本の鎖のようにつながります。これにより、変更履歴を安全かつ効率的に辿ることができるのです。
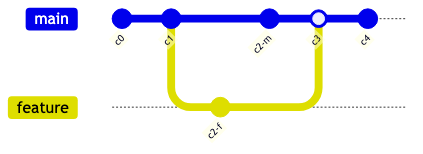
図のキャプション: 各コミットは、親コミットへの参照(ポインタ)を持っています。これにより、コミットの歴史が一本の鎖のようにつながり、変更履歴を辿ることができます。ブランチとは、特定のコミットを指し示す「付箋」にすぎません。
歴史を書き換えても怖くない!Reflogと孤児オブジェクトの探検
では、git reset --hardでコミットを消してしまった時、なぜ復元できるのでしょうか?
それは、Gitがオブジェクトデータベースとは別に、あなたの操作履歴を「Reflog (参照ログ)」としてバックグラウンドで自動的に記録しているからです。これは、HEAD(現在のあなたの場所)や各ブランチの先端が過去にどのコミットIDを指していたかの移動記録です。
これは公式な歴史(コミットツリー)ではなく、あなた専用の「タイムマシンの航行記録」のようなもの。resetやrebaseで歴史を書き換えても、書き換える前の場所がこの記録に残っているため、git reflogコマンドを使えば過去に戻ることができるのです。
さらに一歩進んで、この仕組みを体感してみましょう。
$ echo "This is a new feature." > feature.txt
$ git add feature.txt
$ git commit -m "Add feature.txt"
# この時点でのコミットIDを変数に格納
$ SECOND_COMMIT=$(git rev-parse HEAD)
# コミットの中身を確認すると、親コミット(parent)が記録されていることがわかる
# これでコミットの歴史が繋がっている
$ git cat-file -p $SECOND_COMMIT
#=> tree <tree_hash>
#=> parent <first_commit_hash> (あなたの環境ではハッシュ値が異なります)
#=> author ...
#=> ...
# 間違えてコミットをリセットで消してしまう!
$ git reset --hard HEAD^
# reflogで操作履歴を確認
$ git reflogcommit: Add feature.txt という操作記録と、その時のコミットIDが残っているはずです。
さらに、git fsckというPlumbingコマンドで、どこからも参照されなくなった「孤児オブジェクト」を探すこともできます。
# どこからも参照されていないオブジェクトを探す
$ git fsck --lost-found
#=> dangling commit <消えたコミットのハッシュ> ...dangling commit(ぶら下がっているコミット)として、先ほど消したコミットが見つかりました!
このように、Gitはデータを簡単には捨てない設計になっています。このことを知っているだけで、resetのような強力なコマンドも、自信を持って使えるようになります。
これらの孤児オブジェクトは、git gc (Garbage Collection) というコマンドが実行されると、完全に削除されます。
よくある質問(FAQ)
Q1: git add を実行すると、内部では何が起こっていますか?
A1: 作業ディレクトリにあるファイルの中身からブロブオブジェクトを作成(または再利用)し、その情報(ハッシュ値)をファイル名と共にインデックス(ステージングエリア)に記録します。これが次のコミットの「設計図」になります。
Q2: git commit を実行すると、内部では何が起こっていますか?
A2: 1. インデックスの情報から、ディレクトリ構造を表すツリーオブジェクトが作成されます。 2. そのツリーオブジェクトと親コミット、作者情報、メッセージを含むコミットオブジェクトが作成されます。 3. 現在のブランチが、その新しいコミットオブジェクトを指すように更新されます。
Q3: ファイル名を変えてもリポジトリサイズが大きくならないのはなぜですか?
A3: ファイル名を変更しても、ファイルの中身(データ)が同じであれば、Gitは新しいブロブオブジェクトを作成せず、既存のものを再利用します。インデックスとツリーオブジェクトだけが新しいファイル名で更新されるため、消費するストレージはごくわずかです。
Q4: git reset --hard で消えたコミットはなぜ復元できるのですか?
A4: コミット自体はオブジェクトデータベースからすぐには削除されません。resetはブランチのポインタを過去のコミットに移動させる操作です。reflogにはポインタが移動する前のコミットIDが記録されているため、それを使えば「消えた」ように見えるコミットに再びアクセスできます。
参考資料
この記事で概要を掴んだら、以下の情報源でさらに知識を深めることをお勧めします。公式ドキュメントや著名な開発者のブログは、一次情報として非常に価値があります。
- Pro Git Book – Gitの内側: https://git-scm.com/book/ja/v2/Gitの内側-Gitオブジェクト (日本語)
まとめ
- Gitは、ブロブ・ツリー・コミットという3種類のオブジェクトで、プロジェクトのすべての歴史をスナップショットとして管理しています。
git addはコミットの設計図(インデックス)を作成する操作です。git commitは、インデックスを元にツリーとコミットのオブジェクトを作成する操作です。git cat-fileのようなPlumbingコマンドを使えば、これらのオブジェクトの中身を直接見ることができます。Reflogは、あなたの最後のセーフティネット(安全網)です。
この内部構造のメンタルモデルを持つことで、Gitのあらゆる振る舞いが、より深く、直感的に理解できるようになります!
次のステップへ進もう!
- 関連記事: 第6章 図解:Gitのコミット履歴を修正する3つの方法!git rebase, reflogで失敗も怖くない
- 実践課題: あなたが今関わっているプロジェクトで、
git ls-files --stageを叩いてみましょう!
【挑戦してみよう!演習問題】
reset --hardで消してしまったfeature.txt。コミット全体を戻すのではなく、feature.txtというファイル1つだけを最新の状態に復元するには、どうすれば良いでしょうか?ヒント:
git checkout <コミットID> -- <ファイルパス>というコマンドが使えます。reflogで見つけたコミットIDを使って、試してみましょう!
本記事をご利用いただくにあたって
この記事は、公開時点(2025年9月)の情報に基づき、正確な情報を提供するよう努めています。
しかし、本記事で解説するソフトウェアやサービスの仕様は日々更新されるため、記事内で紹介している画面や手順が、ご覧いただいている時点では変更されている可能性があります。
もし内容に相違がある場合は、各サービスの最新の公式ドキュメントも併せてご参照ください。本記事の情報を利用される際は、ご自身の判断と責任においてお願いいたします。