
なぜPythonでPDFを扱うのか?業務自動化の最前線
PDF(Portable Document Format)は、ビジネス文書、レポート、請求書、学術論文など、あらゆる場面で利用される普遍的なファイル形式です。しかし、その普遍性ゆえに、PDFの作成、編集、データ抽出といった作業は、時に手作業では膨大な時間と労力を要します。
「このPDFから特定の情報を自動で抽出したい…」
「複数のPDFファイルを結合して新しいレポートを作りたい…」
「データベースのデータを使って、動的にPDFの請求書を生成したい…」
このような課題に直面しているなら、Pythonは強力な味方になります。Pythonには、PDFを自在に操るための豊富なライブラリが存在し、これらの課題を解決する道を開くことができます!
図:PDFの構造とPythonでのPDFを扱うイメージ
しかし、PythonのPDFライブラリは多岐にわたり、それぞれに得意なこと、苦手なことがあります。どのライブラリを選べば良いのか、自分のプロジェクトに最適なものはどれなのか、迷ってしまう開発者も少なくないでしょう。
本記事は、そんなあなたのための「Python PDFライブラリ徹底活用ガイド」シリーズの第一歩です。この記事では、Python PDFライブラリの全体像を把握し、あなたのプロジェクト要件に合った最適なライブラリを選定するための重要な基準を解説します。
このシリーズを読み終える頃には、あなたは自信を持ってPDF自動化の次のステップに進めるようになっているでしょう。
対象読者
- Pythonを使ってPDFの操作(生成、編集、読み取りなど)を自動化したいと考えている開発者。
- 複数のPDFライブラリの中から、自身のプロジェクトに最適なものを選びたいと考えている「Pythonでの開発経験が1年未満のジュニアエンジニア」。
- 特に、ライブラリの機能、パフォーマンス、使いやすさ、コミュニティサポートに関心がある方。
動作検証環境
この記事で紹介するPythonを使ったPDF動作は、以下の環境で検証しています。
- OS : macOS Tahoe Version 26.0
- ハードウェア : MacBook Air 2024 M3 24GB
- uv : 0.8.22 (ade2bdbd2 2025-09-23)
- python : 3.13.7
- pypdf : 6.1.1
- PyMuPDF : 1.26.4
- pymupdf-stubs : 1.26.1.post1
- ReportLab : 4.4.4
- charset-normalizer : 3.4.3
- pillow : 11.3.0
- pandas : 2.3.3
- numpy : 2.3.3
- python-dateutil : 2.9.0.post0
- six : 1.17.0
- pytz : 2025.2
- types-pytz : 2025.2.0.20250809
- tzdata : 2025.2
- pandas-stubs : 2.3.2.250926
目次
- Python PDFライブラリ主要3カテゴリ:あなたの目的はどれ?
- 読み込み・テキスト/データ抽出系ライブラリ
- 生成・作成系ライブラリ
- HTML-to-PDF変換系ライブラリ
- Python PDFライブラリ一覧表
- 失敗しない!Python PDFライブラリ選定の5つの重要ポイント
- ポイント1:機能要件(何がしたいか?)
- ポイント2:パフォーマンス要件(処理速度、メモリ使用量)
- ポイント3:日本語対応の有無と注意点
- ポイント4:ライセンスと商用利用
- ポイント5:コミュニティサポートとドキュメント
- 【ロードマップ】Python PDF自動化マスターへの道
- まとめ:最適なライブラリ選定から始めるPDF自動化
- FAQ
- Q1: PythonでPDFを扱うメリットは何ですか?
- Q2: どのライブラリを選べば良いか、まだ迷っています。どうすれば良いですか?
- Q3: 日本語対応が必須なのですが、どのライブラリがおすすめですか?
- Q4: 複数のライブラリを組み合わせるメリットは何ですか?
- 参考資料
- 免責事項
1. Python PDFライブラリ主要3カテゴリ:あなたの目的はどれ?
PythonでPDFを扱うライブラリは、その機能によって大きく3つのカテゴリに分類できます。まずは、それぞれのカテゴリがどのような目的で使われるのかを理解しましょう。
読み込み・テキスト/データ抽出系ライブラリ
このカテゴリのライブラリは、既存のPDFファイルから情報を「読み取る」ことに特化しています。具体的には、PDF内のテキストを抽出したり、ページ数やメタデータなどの情報を取得したり、場合によっては表形式のデータを構造化して抽出したりする機能を提供します。
主なライブラリの例: pypdf, pdfminer.six, PyMuPDF (fitz), pdfplumber, camelot, tabula, slate, unstructured, tika など。
[著者の経験談]: 私は以前、大量の請求書PDFから特定の顧客コードと金額を自動で抽出するシステムを構築した際、このカテゴリのライブラリを複数検討しました。PDFの構造や抽出したいデータの複雑さによって、最適なライブラリが大きく変わることを痛感しましたね。生成・作成系ライブラリ
このカテゴリのライブラリは、Pythonコードを使って新しいPDFファイルを「ゼロから生成する」ことに焦点を当てています。テキスト、画像、図形、表などを配置し、レイアウトを自由に設計して、動的なレポートや帳票を作成する際に利用されます。
主なライブラリの例: ReportLab, PyFPDF, IronPDF など。
[!NOTE]: これらのライブラリは、既存のPDFを編集する機能も一部持ち合わせていることがありますが、主な用途は新規作成です。HTML-to-PDF変換系ライブラリ
Webアプリケーションで生成したHTMLコンテンツをPDFとして出力したい場合に便利なのが、このカテゴリのライブラリです。HTMLとCSSの知識を活用してPDFを作成できるため、Web開発者にとっては親しみやすいアプローチと言えるでしょう。
主なライブラリの例: django-wkhtmltopdf, django_xhtml2pdf, WeasyPrint など。
[!TIP]: Webフレームワーク(Djangoなど)と連携するライブラリが多いですが、スタンドアロンでHTMLをPDFに変換できるツールもあります。Python PDFライブラリ一覧表
| ライブラリ名 | 主要カテゴリ | 主な機能 |
|---|---|---|
pypdf | 読み込み・テキスト/データ抽出系 | 既存PDFからの情報読み取り、テキスト抽出、ページ数やメタデータ取得、結合・分割、回転、透かし追加、フォーム操作、セキュリティ |
pdfminer.six | 読み込み・テキスト/データ抽出系 | 既存PDFからの情報読み取り、テキスト抽出、ページ数やメタデータ取得、表形式データ抽出 |
PyMuPDF (fitz) | 読み込み・テキスト/データ抽出系 | 既存PDFからの情報読み取り、テキスト抽出、ページ数やメタデータ取得、表形式データ抽出、画像抽出、変換、編集、レンダリング、注釈操作 |
pdfplumber | 読み込み・テキスト/データ抽出系 | 既存PDFからの情報読み取り、テキスト抽出、ページ数やメタデータ取得、表形式データ抽出 |
camelot | 読み込み・テキスト/データ抽出系 | 既存PDFからの情報読み取り、テキスト抽出、ページ数やメタデータ取得、表形式データ抽出 |
tabula | 読み込み・テキスト/データ抽出系 | 既存PDFからの情報読み取り、テキスト抽出、ページ数やメタデータ取得、表形式データ抽出 |
slate | 読み込み・テキスト/データ抽出系 | 既存PDFからの情報読み取り、テキスト抽出、ページ数やメタデータ取得、表形式データ抽出 |
unstructured | 読み込み・テキスト/データ抽出系 | 既存PDFからの情報読み取り、テキスト抽出、ページ数やメタデータ取得、表形式データ抽出 |
tika | 読み込み・テキスト/データ抽出系 | 既存PDFからの情報読み取り、テキスト抽出、ページ数やメタデータ取得、表形式データ抽出 |
ReportLab | 生成・作成系 | 新規PDF生成、テキスト、画像、図形、表の配置、レイアウト設計、動的なレポートや帳票作成、既存PDF編集(一部) |
PyFPDF | 生成・作成系 | 新規PDF生成、テキスト、画像、図形、表の配置、レイアウト設計、動的なレポートや帳票作成、既存PDF編集(一部) |
IronPDF | 生成・作成系 | 新規PDF生成、テキスト、画像、図形、表の配置、レイアウト設計、動的なレポートや帳票作成、既存PDF編集(一部) |
django-wkhtmltopdf | HTML-to-PDF変換系 | HTMLコンテンツをPDFに変換 |
django_xhtml2pdf | HTML-to-PDF変換系 | HTMLコンテンツをPDFに変換 |
WeasyPrint | HTML-to-PDF変換系 | HTMLコンテンツをPDFに変換 |
2. 失敗しない!Python PDFライブラリ選定の5つの重要ポイント
最適なPDFライブラリを選ぶためには、単に機能を知るだけでなく、プロジェクトの具体的な要件と照らし合わせて評価することが不可欠です。ここでは、選定時に考慮すべき主要なポイントを解説します。
ポイント1:機能要件(何がしたいか?)
最も基本的な選定基準です。あなたのプロジェクトでPDFに対して「何をしたいのか」を明確にしましょう。
- テキスト抽出: PDFから文字情報を取得したい。
- データ抽出: PDF内の表や特定のフォーマットのデータを構造化して取得したい。
- PDF生成: 新しいPDFをPythonコードで作成したい。
- PDF編集: 既存のPDFのページを結合・分割したり、回転させたり、透かしを追加したりしたい。
- フォーム操作: PDFフォームのデータを読み書きしたい。
- セキュリティ: PDFにパスワードを設定したり、暗号化したりしたい。
- HTML変換: HTMLコンテンツをPDFに変換したい。
これらの機能のうち、どれが必須で、どれがオプションなのかをリストアップすることで、候補となるライブラリを絞り込むことができます。
ポイント2:パフォーマンス要件(処理速度、メモリ使用量)
大量のPDFファイルを処理する場合や、リアルタイム性が求められるシステムでは、ライブラリのパフォーマンスが非常に重要になります。
- 処理速度: 1ファイルあたりの処理時間、または1秒あたりに処理できるファイル数。
- メモリ使用量: 大容量のPDFを扱う際に、システムメモリをどの程度消費するか。
[著者の経験談]: 私はかつて、数千ページに及ぶ巨大なPDFからテキストを抽出するタスクに直面しました。当初選んだライブラリではメモリ不足で処理が中断してしまい、よりメモリ効率の良いライブラリに切り替える必要がありました。事前に小規模なベンチマークテストを行うことを強くお勧めします。ポイント3:日本語対応の有無と注意点
日本の開発者にとって、日本語のPDFを扱う際の対応は非常に重要なポイントです。
- テキスト抽出時の文字化け: 日本語特有のエンコーディングやフォントの問題で、テキストが正しく抽出されないことがあります。
- PDF生成時の日本語フォント埋め込み: 日本語を含むPDFを生成する際、適切なフォントを埋め込まないと、表示環境によって文字化けが発生する可能性があります。
[!NOTE]: 日本語対応は、ライブラリによって大きく異なります。特にテキスト抽出の精度や、フォント埋め込みの手間は要確認です。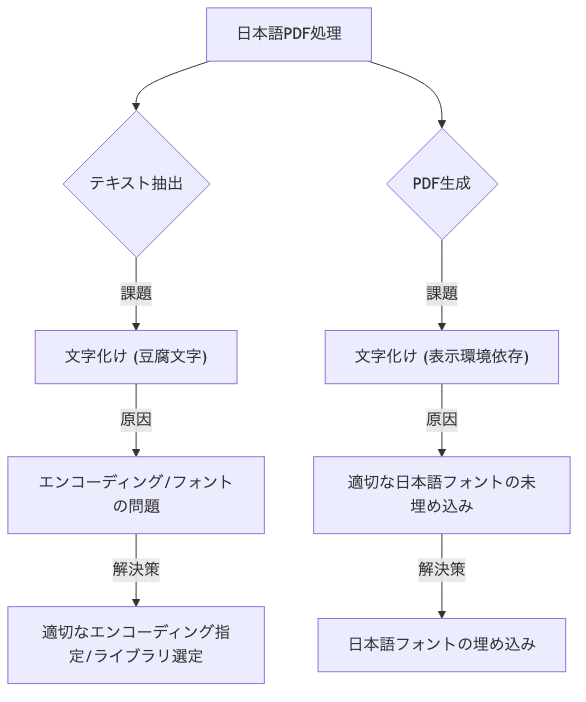
図:PDFの日本語対応の処理と注意点
ポイント4:ライセンスと商用利用
プロジェクトが商用利用される場合、ライブラリのライセンスは必ず確認すべき項目です。
- オープンソースライセンス: MIT License, Apache License, GPLなど。商用利用が可能なものが多いですが、GPLのように派生作品にもGPLを適用する必要があるものもあります。
- 商用ライセンス: 一部のライブラリは、商用利用の場合に有償ライセンスが必要となることがあります。
ポイント5:コミュニティサポートとドキュメント
問題が発生した際に、解決策を見つけやすいかどうかは、開発効率に直結します。
- ドキュメントの充実度: 公式ドキュメントが分かりやすいか、サンプルコードが豊富か。
- コミュニティの活発さ: GitHubのIssueやStack Overflowなどで、質問に対する回答が得られやすいか。
- 最終更新日: ライブラリが活発にメンテナンスされているか。
3. 【ロードマップ】Python PDF自動化マスターへの道
この「Python PDFライブラリ徹底活用ガイド」シリーズでは、主要なPDFライブラリを深掘りし、実践的なコード例とユースケースを通して、あなたのPDF自動化スキルを向上させることを目指します。
以下が本シリーズのロードマップです。
- 記事1: Python PDFライブラリ徹底比較:初心者向け選定ガイドと活用ロードマップ
- 記事2: pypdf入門:PythonでPDFの基本操作とテキスト抽出をマスターする
- 記事3: pypdf実践:PDFの結合・分割、ページ操作でドキュメントを効率化する
- 記事4: pypdf応用:PDFフォームデータ操作とセキュリティ設定で業務を自動化
- 記事5: ReportLab入門:PythonでPDFをゼロから生成する基礎
- 記事6: ReportLab実践:複雑なレイアウトとグラフ描画でプロフェッショナルなPDFを作成
- 記事7: ReportLab応用:動的データからの帳票生成と日本語対応の完全ガイド
- 記事8: PyMuPDF入門:高速PDF処理と日本語テキスト抽出の最前線
- 記事9: PyMuPDF実践:PDFからの画像抽出、変換、そして編集テクニック
- 記事10: PyMuPDF応用:高度なレンダリング、注釈操作、そして複数ライブラリ連携
このロードマップに沿って学習することで、単一のライブラリの知識だけでなく、複数のライブラリを組み合わせたPDF処理ワークフローを構築するスキルも身につけることができます。
4. まとめ:最適なライブラリ選定から始めるPDF自動化
本記事では、Python PDFライブラリの全体像と、あなたのプロジェクトに最適なライブラリを選定するための重要な基準を解説しました。
- PDFライブラリは「読み込み・抽出」「生成・作成」「HTML-to-PDF変換」の3つの主要カテゴリに分けられる。
- 選定時には「機能要件」「パフォーマンス要件」「日本語対応」「ライセンス」「コミュニティサポート」を総合的に評価することが重要。
- 本シリーズは、各ライブラリの詳細な使い方から、複数ライブラリ連携による高度な自動化までを網羅する学習ロードマップを提供する。
最適なライブラリ選定への第一歩は、まずあなたのプロジェクトで「何をしたいか」を明確にすることです。そして、本シリーズの次の記事を読み進め、各ライブラリの具体的な使い方を学び、あなたのPDF自動化の旅を加速させていきましょう。
5. FAQ
Q1: PythonでPDFを扱うメリットは何ですか?
A1: PythonでPDFを扱う最大のメリットは、自動化と効率化です。手作業では時間と手間がかかるPDF関連のタスク(データ抽出、レポート生成、ファイル結合など)を、プログラムによって自動実行できるようになります。これにより、ヒューマンエラーの削減、作業時間の短縮、そしてより複雑なワークフローの実現が可能になります。
Q2: どのライブラリを選べば良いか、まだ迷っています。どうすれば良いですか?
A2: まずは、あなたのプロジェクトで最も優先度の高い「機能要件」を明確にしてください。例えば、単にテキストを抽出したいだけであればPyPDF2やPyMuPDFが有力な候補になりますし、ゼロからPDFを生成したいのであればReportLabが適しています。本シリーズの各記事で、それぞれのライブラリの具体的な使い方や得意分野を詳しく解説していきますので、そちらを参考にしながら、あなたのニーズに最も合致するライブラリを見つけていきましょう。
Q3: 日本語対応が必須なのですが、どのライブラリがおすすめですか?
A3: 日本語対応の観点では、テキスト抽出の精度やフォント埋め込みの容易さでライブラリ間に差があります。一般的に、PyMuPDFは日本語テキスト抽出において高い精度を誇ります。PDF生成においては、ReportLabも日本語フォントの埋め込みに対応していますが、設定に一手間かかる場合があります。各ライブラリの詳細記事で、日本語対応に関する具体的な解説とコード例を提供しますので、そちらをご確認ください。
Q4: 複数のライブラリを組み合わせるメリットは何ですか?
A4: 単一のライブラリでは実現が難しい、より高度で複雑なPDF処理ワークフローを構築できる点が最大のメリットです。例えば、PyMuPDFでPDFから高速にテキストや画像を抽出し、そのデータを元にReportLabで新しいレポートを生成するといった連携が可能です。それぞれのライブラリの「得意技」を組み合わせることで、より柔軟で強力なPDF自動化システムを構築できます。
6. 参考資料
- pypdf 公式ドキュメント: https://pypdf.readthedocs.io/en/stable/
- ReportLab 公式サイト: https://docs.reportlab.com/
- PyMuPDF 公式ドキュメント: https://pymupdf.readthedocs.io/en/latest/
7. 免責事項
本記事および本シリーズは、Python PDFライブラリに関する一般的な情報と筆者の経験に基づいています。ライブラリの機能、パフォーマンス、ライセンス、日本語対応などは、バージョンアップや環境によって異なる場合があります。実際のプロジェクトに導入する際は、必ず公式ドキュメントを参照し、ご自身の責任において検証を行ってください。