
確かな一歩を踏み出す、モダンJavaバッチ開発の世界へ
前回の記事で、VS Codeを中心としたJava 25とSpring Boot 3.5.7で新たなバッチ開発環境を整えることできました。
今回は、その基盤の上に、具体的なバッチアプリケーション開発の「基礎」を築いていきます。
本記事では、ただ概念を学ぶだけでなく、実際に手を動かしながらSpring Batchの根幹をなす要素を理解し、シンプルなバッチアプリケーションを構築するまでを徹底的に解説します。
Java 25の新機能がバッチ処理にどのような恩恵をもたらすのか、具体的なコード例を交えながら深掘りしていきましょう。
さあ、最先端の技術を駆使して、あなたのバッチ開発スキルを次のレベルへと引き上げましょう!
目次
- 1. Spring Batchの基本概念:バッチ処理の「心臓部」を理解する
- 1-1. Spring Batchのアーキテクチャ
- 1-2. Job, Step, ItemReader, ItemProcessor, ItemWriterとは
- 2. Spring Boot 3.5.7でのSpring Batch設定:最小限の労力でバッチを起動する
- 2-1. 新規のプロジェクトを作成する場合
- 2-2. 既存のプロジェクトへ追加する場合:必要な依存関係の追加
- 2-3. 既存のプロジェクトへ追加する場合:バッチ設定クラスの作成
- 3. シンプルなバッチジョブの実装:CSVを読み込み、加工し、出力する
- 3-1. ItemReader, ItemProcessor, ItemWriterの実装クラス例
- 3-2. バッチ設定クラスでのJob/Step定義
- 4. Java 25の新機能とSpring Bootバッチへの影響:未来のバッチ処理を覗く
- 4-1. 主要な新機能の紹介 (例: Virtual Threads, Pattern Matching for switchなど)
- 4-2. バッチ処理における活用例
- まとめと次のステップ:基礎から実践への架け橋
対象読者
- Spring Batchの基本概念を学びたい方
- Spring Boot 3.5.7とJava 25を使ったバッチ開発に興味がある方
- CSVファイルの読み込み、加工、出力を行うバッチ処理の実装方法を知りたい方
- Java 25の新機能がバッチ処理に与える影響について知りたい方
1. Spring Batchの基本概念:バッチ処理の「心臓部」を理解する
Spring Batchは、エンタープライズ級の強力なバッチ処理を構築するためのフレームワークです。
大量データを扱うための堅牢性、再起動可能性、スケールアウトといった特性を、開発者が意識しなくても利用できるよう設計されています。
1-1. Spring Batchのアーキテクチャ
Spring Batchは、これらのコンポーネントを基盤として、以下のようなアーキテクチャを提供します。
Spring Batchの主要コンポーネント間のデータフローと制御フローは、JobLauncherがJobを起動し、Jobは複数のStepで構成されます。
各StepはItemReader, ItemProcessor, ItemWriterからなるChunk指向処理、またはTasklet処理を実行し、その実行状態はJobRepositoryに記録されます。
図:Spring Batchの主要コンポーネント間のデータフローと制御フロー
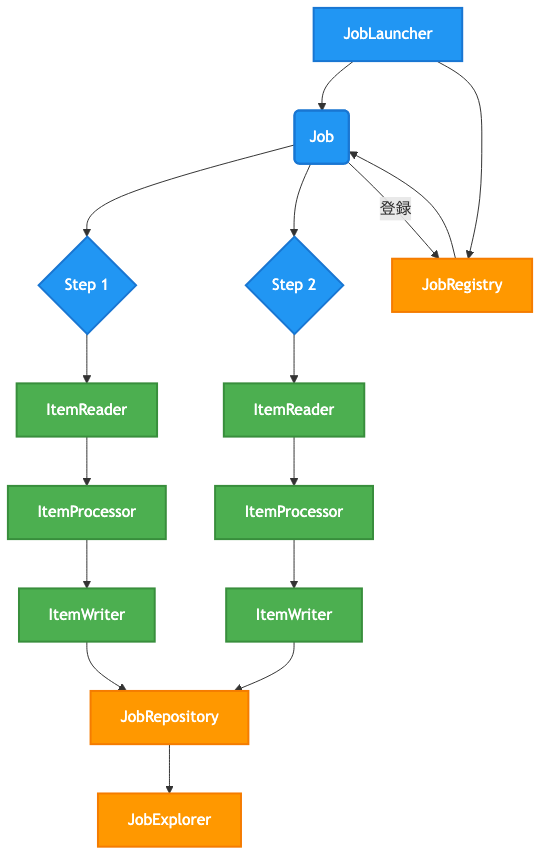
- JobLauncher: ジョブを開始するためのインターフェースです。
- JobRegistry: システム内のジョブを追跡し、名前でジョブを起動できるようにします。
- JobRepository: バッチジョブのメタデータ(実行履歴、ステータス、開始・終了時刻など)を永続化する役割を担います。これにより、ジョブの再起動や監視が可能になります。
- JobExplorer: 実行中のJobやJobRepositoryに保存されているメタデータにアクセスするためのインターフェースです。
このアーキテクチャにより、バッチ処理のライフサイクル管理、状態管理、エラーからの回復といった複雑な課題が抽象化され、開発者はビジネスロジックの実装に集中できます。
1-2. Job, Step, ItemReader, ItemProcessor, ItemWriterとは
Spring Batchを理解する上で、核となるのが以下の主要コンポーネントです。
- Job (ジョブ):
- 複数のStepをまとめたバッチ処理全体を指します。例えるなら、一本の映画全体のようなイメージです。
- Step (ステップ):
- ジョブを構成する個々の独立した処理単位です。映画のワンシーンのように、データ読み込み、加工、書き込みなどの特定のタスクを実行します。
- Stepには主に「Chunk指向処理」と「Tasklet処理」の2種類があります。今回は主にChunk指向処理に焦点を当てます。
- ItemReader (アイテムリーダー):
- データを読み込む役割を担います。ファイル(CSV, XMLなど)、データベース、Webサービスなど、様々なデータソースからレコード(アイテム)を一つずつ読み込みます。
- まるで図書館の司書が本棚から一冊ずつ本を取り出すように、データを取得します。
- ItemProcessor (アイテムプロセッサー):
- ItemReaderが読み込んだデータを加工する役割を担います。ビジネスロジックの適用、フィルタリング、データ変換などを行います。
- 読み込んだ本の内容を要約したり、特定のキーワードを抽出したりする作業に似ています。
- ItemWriter (アイテムライター): ItemProcessorで加工されたデータを書き込む役割を担います。ファイル、データベース、メッセージキューなど、様々な出力先にデータを書き込みます。
- 加工済みの本を新しい書式でノートに書き写すようなものです。
これらのコンポーネントが連携することで、一連のバッチ処理が実現されます。
2. Spring Boot 3.5.7でのSpring Batch設定:最小限の労力でバッチを起動する
Spring Bootを使用すると、Spring Batchの設定は驚くほど簡単になります。自動設定の恩恵を最大限に活用しつつ、必要なカスタマイズを加えていきましょう。
2-1. 新規のプロジェクトを作成する場合
Spring Batchのプロジェクト作成、単なサンプルバッチ処理の実装、実行確認の手順を以下の記事で詳細に解説していますので、是非ご覧ください。
2-2. 既存のプロジェクトへ追加する場合:必要な依存関係の追加
pom.xml (Maven) または build.gradle (Gradle) に、Spring Boot Starter BatchとLombokを追加します。
例:Mavenの場合
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-batch</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.batch</groupId>
<artifactId>spring-batch-test</artifactId>
<scope>test</scope>
</dependency>
<dependency>
<groupId>org.postgresql</groupId>
<artifactId>postgresql</artifactId>
<scope>runtime</scope>
</dependency>
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<optional>true</optional>
</dependency>例:Gradleの場合:
implementation 'org.springframework.boot:spring-boot-starter-batch'
testImplementation 'org.springframework.batch:spring-batch-test'
runtimeOnly 'org.postgresql:postgresql'
runtimeOnly 'com.h2database:h2'
compileOnly 'org.projectlombok:lombok'
annotationProcessor 'org.projectlombok:lombok'
testCompileOnly 'org.projectlombok:lombok'
testAnnotationProcessor 'org.projectlombok:lombok'データベースへのアクセスが必要な場合は、Spring Boot Starter Data JPAとPostgreSQL Driver、または開発・テスト用にH2 Databaseを追加します。
Spring BatchはJobRepositoryにメタデータを保存するため、RDBMS(リレーショナルデータベース管理システム)が必要です。
本番環境ではPostgreSQLのような永続的なデータベースを推奨しますが、開発・テスト時にはH2のようなインメモリデータベースが便利です。
2-3. 既存のプロジェクトへ追加する場合:バッチ設定クラスの作成
Spring Boot 3.5.7では、spring-boot-starter-batch を依存関係に追加するだけで、Spring Batchの自動設定が有効になります。
そのため、@EnableBatchProcessing アノテーションを明示的に付与する必要はありません。Spring Bootが自動的に必要なコンポーネント(JobRepository, JobLauncherなど)を設定してくれます。
src/main/java/com/example/batch/BatchConfig.java
import org.springframework.context.annotation.Configuration;
@Configuration
public class BatchConfig {
// ここにJobやStepの定義を追加していきます
}これで、Spring Batchがアプリケーションに組み込まれる準備が整いました。
3. シンプルなバッチジョブの実装:CSVを読み込み、加工し、出力する
それでは、実際にSpring Batchを使って簡単なバッチジョブを実装してみましょう。
ここでは、「CSVファイルを読み込み、各行のデータを大文字に変換し、新しいCSVファイルに出力する」というシナリオを考えます。
3-1. ItemReader, ItemProcessor, ItemWriterの実装クラス例
ここでは、Lombokを使用してデータモデルを簡潔に定義します。Lombokの導入については、「必要な依存関係の追加」セクションを参照してください。
まず、データモデルを定義します。
InputDataの実装 (CSVファイルから読み込む例):
// src/main/java/com/example/batch/model/InputData.java
package com.example.my_batch_app.batch.model;
import lombok.Data;
@Data
public class InputData {
private long id;
private String firstName;
private String lastName;
}OutputDataの実装 (CSVファイルに書き込む例):
// src/main/java/com/example/batch/model/OutputData.java
package com.example.my_batch_app.batch.model;
import lombok.Data;
@Data
public class OutputData {
private long id;
private String firstName;
private String lastName;
}次に、CSVファイルの読み込み、変換、書き込みを実装します。
ItemReaderの実装 (CSVファイルから読み込む例):
// src/main/java/com/example/batch/reader/CsvItemReader.java
package com.example.my_batch_app.batch.reader;
import com.example.my_batch_app.batch.model.InputData;
import org.springframework.batch.item.file.FlatFileItemReader;
import org.springframework.batch.item.file.mapping.BeanWrapperFieldSetMapper;
import org.springframework.batch.item.file.mapping.DefaultLineMapper;
import org.springframework.batch.item.file.transform.DelimitedLineTokenizer;
import org.springframework.core.io.ClassPathResource;
public class CsvItemReader extends FlatFileItemReader<InputData> {
public CsvItemReader() {
this.setResource(new ClassPathResource("data/input.csv")); // input.csvを読み込む
this.setLinesToSkip(1); // ヘッダー行をスキップ
DefaultLineMapper<InputData> lineMapper = new DefaultLineMapper<>();
DelimitedLineTokenizer tokenizer = new DelimitedLineTokenizer();
tokenizer.setNames("id", "firstName", "lastName"); // CSVの列名
BeanWrapperFieldSetMapper<InputData> fieldSetMapper =
new BeanWrapperFieldSetMapper<>();
fieldSetMapper.setTargetType(InputData.class);
lineMapper.setLineTokenizer(tokenizer);
lineMapper.setFieldSetMapper(fieldSetMapper);
this.setLineMapper(lineMapper);
}
}ItemProcessorの実装 (データを大文字に変換する例):
// src/main/java/com/example/batch/processor/UpperCaseItemProcessor.java
package com.example.my_batch_app.batch.processor;
import com.example.my_batch_app.batch.model.InputData;
import com.example.my_batch_app.batch.model.OutputData;
import org.springframework.batch.item.ItemProcessor;
public class UpperCaseItemProcessor
implements ItemProcessor<InputData, OutputData> {
@Override
public OutputData process(InputData item) throws Exception {
OutputData output = new OutputData();
output.setId(item.getId());
output.setFirstName(item.getFirstName());
output.setLastName(item.getLastName().toUpperCase()); // 大文字に変換
return output;
}
}ItemWriterの実装 (CSVファイルに書き込む例):
// src/main/java/com/example/batch/writer/CsvItemWriter.java
package com.example.my_batch_app.batch.writer;
import com.example.my_batch_app.batch.model.OutputData;
import org.springframework.batch.item.file.FlatFileItemWriter;
import org.springframework.batch.item.file.transform.BeanWrapperFieldExtractor;
import org.springframework.batch.item.file.transform.DelimitedLineAggregator;
import org.springframework.core.io.FileSystemResource;
public class CsvItemWriter extends FlatFileItemWriter<OutputData> {
public CsvItemWriter() {
this.setResource(new FileSystemResource("target/output.csv")); // output.csvに書き込む
this.setHeaderCallback(writer -> writer.write("id,firstName,lastName")); // ヘッダー行
this.setAppendAllowed(false); // 毎回新規作成
DelimitedLineAggregator<OutputData> lineAggregator =
new DelimitedLineAggregator<>();
BeanWrapperFieldExtractor<OutputData> fieldExtractor =
new BeanWrapperFieldExtractor<>();
fieldExtractor.setNames(new String[] { "id", "firstName", "lastName" });
lineAggregator.setFieldExtractor(fieldExtractor);
this.setLineAggregator(lineAggregator);
}
}3-2. バッチ設定クラスでのJob/Step定義
上記のコンポーネントを使って、JobとStepを定義します。
JobとStepの実装(CSVファイル処理の例):
// src/main/java/com/example/batch/config/BatchConfig.java (続き)
package com.example.my_batch_app.batch.config;
import org.springframework.batch.core.Job;
import org.springframework.batch.core.Step;
import org.springframework.batch.core.job.builder.JobBuilder;
import org.springframework.batch.core.repository.JobRepository;
import org.springframework.batch.core.step.builder.StepBuilder;
import org.springframework.batch.item.ItemProcessor;
import org.springframework.batch.item.ItemReader;
import org.springframework.batch.item.ItemWriter;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.transaction.PlatformTransactionManager;
import com.example.my_batch_app.batch.model.InputData;
import com.example.my_batch_app.batch.model.OutputData;
import com.example.my_batch_app.batch.reader.CsvItemReader;
import com.example.my_batch_app.batch.processor.UpperCaseItemProcessor;
import com.example.my_batch_app.batch.writer.CsvItemWriter;
@Configuration
public class BatchConfig {
private final JobRepository jobRepository;
private final PlatformTransactionManager transactionManager;
public BatchConfig(JobRepository jobRepository, PlatformTransactionManager transactionManager) {
this.jobRepository = jobRepository;
this.transactionManager = transactionManager;
}
@Bean
public ItemReader<InputData> csvItemReader() {
return new CsvItemReader();
}
@Bean
public ItemProcessor<InputData, OutputData> upperCaseItemProcessor() {
return new UpperCaseItemProcessor();
}
@Bean
public ItemWriter<OutputData> csvItemWriter() {
return new CsvItemWriter();
}
@Bean
public Step processCsvStep() {
return new StepBuilder("processCsvStep", jobRepository)
.<InputData, OutputData>chunk(10, transactionManager) // 10件ずつコミット
.reader(csvItemReader())
.processor(upperCaseItemProcessor())
.writer(csvItemWriter())
.build();
}
@Bean
public Job csvProcessingJob() {
return new JobBuilder("csvProcessingJob", jobRepository)
.start(processCsvStep())
.build();
}
}サンプルデータ:
/src/main/resources/data/input.csv
id,firstName,lastName
1,John,Doe
2,Jane,Smith
3,Peter,Jones
4,Mary,Johnson
5,David,Williamsこれで、簡単なCSV処理バッチが完成しました。
ビルドを実行します。
./mvnw clean packageビルドが成功したら、先ほど説明したようにジョブを実行できます。
csvProcessingJob を実行するには:
java -jar target/my-batch-app-0.0.1-SNAPSHOT.jar --spring.batch.job.name=csvProcessingJob./mvnw spring-boot:runを使う場合でも、実行するジョブ名を指定する必要があります。そのためには、以下のように-Dspring-boot.run.arguments` を使ってアプリケーションに引数を渡します。
csvProcessingJob を実行する場合:
./mvnw spring-boot:run -Dspring-boot.run.arguments="--spring.batch.job.name=csvProcessingJob"このように、起動方法に応じて適切な方法で引数を渡すことで、意図したジョブを実行できます。
実行した結果は、以下のファイルに出力されます。
target/output.csv
id,firstName,lastName
1,John,DOE
2,Jane,SMITH
3,Peter,JONES
4,Mary,JOHNSON
5,David,WILLIAMS4. Java 25の新機能とSpring Bootバッチへの影響:未来のバッチ処理を覗く
Javaは進化を続けており、各リリースで新しい機能が追加されています。Java 25は、特にバッチ処理の分野においても、そのパフォーマンスと開発効率に大きな影響を与える可能性を秘めています。
4-1. 主要な新機能の紹介 (例: Virtual Threads, Pattern Matching for switchなど)
Java 25の新機能の一部を、バッチ処理の観点から見てみましょう。
- Virtual Threads (仮想スレッド):
- 軽量なスレッドであり、スレッドプールの管理オーバーヘッドを大幅に削減します。
- バッチ処理への影響: 多数の並行I/O処理や、多数の小さなタスクを並列実行するバッチにおいて、スループットの向上とリソース消費の削減が期待できます。従来のプラットフォームスレッドではリソースの限界があった並列処理が、より手軽に実現できるようになります。Spring Batchの
TaskExecutorとの組み合わせで、より効率的な並列処理が可能になるでしょう。
- Pattern Matching for
switch(switchのパターンマッチング):switch式や文で、型に基づいて値を照合し、それに合わせて異なる処理を実行する機能です。コードの簡潔さと可読性を向上させます。- バッチ処理への影響:
ItemProcessor内で、入力データの型に応じて複雑な変換ロジックを記述する際に、より簡潔で安全なコードが書けるようになります。例えば、複数の異なるデータフォーマットが混在する入力ファイルを処理する場合などに威力を発揮します。
これらの新機能は、現在Spring BootやSpring Batchで直接的に活用できるわけではありませんが、今後のフレームワークのアップデートや、カスタムコンポーネントの実装において、その恩恵を受けることになります。
4-2. バッチ処理における活用例
Java 25の新機能を念頭に置いた、将来的なバッチ処理の活用例をいくつかご紹介します。
- Virtual Threadsを活用した高並列データ取得:
- 例えば、複数の外部APIからデータを取得し、それを並列で加工・集計するようなバッチ処理において、
ItemReader内でVirtual Threadsを使用することで、I/O待機中のスレッドリソースを効率的に活用し、全体のスループットを向上させることができます。 - Spring Batchの
MultiResourceItemReaderと組み合わせて、大量のファイルを並列で読み込む際にも効果を発揮するでしょう。
- 例えば、複数の外部APIからデータを取得し、それを並列で加工・集計するようなバッチ処理において、
- Pattern Matching for
switchによる柔軟なデータ変換:- 異なるスキーマを持つJSONやXMLデータを処理する
ItemProcessorにおいて、InputDataオブジェクトの型や内部の値に応じて、異なる変換ロジックをswitch文でスマートに記述できます。これにより、コードの複雑性を軽減し、保守性を高めることができます。
- 異なるスキーマを持つJSONやXMLデータを処理する
これらの例は、Java 25がもたらす可能性のほんの一部です。
常に最新のJavaの動向を追いかけ、Spring Boot/Batchエコシステムとの連携に注目することで、より効率的でパワフルなバッチアプリケーションを開発できるでしょう。
まとめと次のステップ:基礎から実践への架け橋
本記事では、Spring BootとSpring Batchの基礎の基礎を学び、シンプルなCSV処理バッチの実装を通して、その主要コンポーネント(Job, Step, ItemReader, ItemProcessor, ItemWriter)の役割と連携を深く理解しました。さらに、Java 25の注目すべき新機能が、未来のバッチ処理にどのような可能性をもたらすかについても考察しました。
この知識は、堅牢でスケーラブルなバッチアプリケーションを構築するための確かな土台となります。しかし、バッチ開発の旅はまだ始まったばかりです。
次回の記事では、より複雑なビジネス要件に対応するためのSpring Batchの高度な機能と設計パターン、そして堅牢なバッチ処理を実現するためのエラーハンドリングや再起動戦略について深掘りしていきます。
今回学んだ基礎をしっかりと定着させ、来るべき実践編に備えましょう。継続的な学習と実践が、あなたのスキルを飛躍的に向上させる鍵となります。
免責事項
本記事は、執筆時点での情報に基づいており、将来的に情報が変更される可能性があります。本記事の内容によって生じたいかなる損害についても、筆者は一切の責任を負いません。読者の皆様ご自身の判断と責任において、本記事の情報をご活用ください。