
Spring Batchの高度な機能:複雑な処理をシンプルに
「Spring Batchって何から始めればいいの?」
「Chunk処理とTasklet、どう使い分けるの?」
「複雑なジョブの流れをどうやって制御するんだろう?」
Spring Batchを使い始める際、これらの疑問に直面する開発者は少なくありません。
Spring Batchは、その柔軟性と拡張性によって、様々なバッチ処理の要件に対応できます。
ここでは、特に複雑な処理をシンプルに記述するための主要な機能を見ていきましょう。
本記事では、複雑な処理をシンプルに記述するためのSpring Batchの主要な処理モデルであるChunk指向処理とTasklet、そして複数の処理ステップを柔軟に組み合わせるジョブフロー制御について、初心者にも分かりやすく解説します。
Spring Batchの強力な機能を理解し、効率的で読みやすいバッチ処理を設計するための第一歩を踏み出しましょう。
目次
- Chunk指向処理の詳細と最適化
1-1. Chunk指向処理のライフサイクル:Read-Process-Writeの連携
1-2. Chunk指向処理の概念イメージ解説
1-3. コミットインターバル(Chunkサイズ)の具体的な設定方法と考慮事項 - Taskletによる非Chunk処理:単一操作のバッチ処理をシンプルに
2-1. Taskletの処理フロー
2-2. Taskletの作成
2-3. TaskletAdapterによる既存クラスの活用 - Flow, Split, Deciderによるジョブフロー制御:複雑なバッチ処理のオーケストレーション
3-1. 順次フロー (Sequential Flow)
3-2. 条件付きフロー (Conditional Flow)
3-3. 並行フロー (Split Flows)
3-4. Deciderによるプログラム的フロー決定
3-5. ジョブの終了ステータス制御 - まとめ
対象読者
- Spring Batchの基本的な概念や使い方を学びたい方
- Javaでのバッチ処理開発に携わる方、またはこれから携わる予定の方
- 複雑なバッチ処理の設計や実装に課題を感じている方
- Spring BatchのChunk処理、Tasklet、ジョブフロー制御について理解を深めたい方
1. Chunk指向処理の詳細と最適化
Spring Batchは、その最も一般的な実装において「Chunk指向」の処理スタイルを使用しています。
チャンク指向処理とは、データを1つずつ読み込み、トランザクション境界内で書き出される「Chunk」を作成することを指します。
具体的には、データを「読み込み(Read)」「処理(Process)」「書き込み(Write)」という一連のチャンク(塊)で処理するモデルです。
読み込まれたアイテムの数がコミット間隔に達すると、ItemWriterによってチャンク全体が書き出され、その後トランザクションがコミットされます。
1-1. Chunk指向処理のライフサイクル:Read-Process-Writeの連携
Chunk指向処理は、以下の3つの主要なコンポーネントが連携して動作するライフサイクルを持っています。このサイクルを繰り返すことで、大量のデータを効率的かつ堅牢に処理します。
- ItemReader (
ItemReader<T>):- 役割:
- データソースから1件ずつデータを読み込みます。
- ファイル、データベース、メッセージキューなど、様々なデータソースに対応する実装が提供されています(例:
FlatFileItemReader,JdbcCursorItemReader)。
- 特徴:
- 読み込むデータがなくなると
nullを返します。
- 読み込むデータがなくなると
- 役割:
- ItemProcessor (
ItemProcessor<I, O>):- 役割:
ItemReaderが読み込んだデータを加工・変換します。- ビジネスロジックの適用、データのフィルタリング、フォーマット変換などを行います。
- このコンポーネントはオプションであり、不要な場合はスキップできます。
- 特徴:
- 処理結果が不要な場合やフィルタリングで除外したい場合は
nullを返します。
- 処理結果が不要な場合やフィルタリングで除外したい場合は
- 役割:
- ItemWriter (
ItemWriter<T>):- 役割:
ItemProcessorによって加工済み、またはItemReaderから直接読み込まれたデータをまとめて(チャンクとして)永続化します。- ファイル、データベース、Webサービスなど、様々な出力先に書き込む実装があります(例:
FlatFileItemWriter,JdbcBatchItemWriter)。
- 特徴:
- 複数のアイテムをリストとして受け取り、一括で書き込みます。
- 役割:
NOTE:
このRead-Process-Writeのサイクルは、設定された「コミットインターバル(chunkサイズ)」に達するまで繰り返されます。
コミットインターバルに達すると、読み込まれたアイテムの塊(チャンク)がItemWriterに渡され、一括で書き込まれた後、トランザクションがコミットされます。
この仕組みにより、メモリ効率を保ちながら大量データを処理し、かつ途中でエラーが発生しても前回のコミットポイントから安全に再開できる「再起動可能性」が保証されます。
1-2. Chunk指向処理の概念イメージ解説
以下に、Chunk指向処理の概念を簡略化した擬似コードで示します。commitIntervalは、Spring Batchの設定で定義されるチャンクサイズを指します。
ItemProcessorなしの場合:
List<Object> items = new ArrayList<>(); // 読み込んだアイテムを一時的に保持するリスト
for(int i = 0; i < commitInterval; i++){ // コミットインターバルに達するまでアイテムを読み込む
Object item = itemReader.read(); // ItemReaderから1件読み込み
if (item != null) {
items.add(item); // リストに追加
} else {
break; // 読み込むアイテムがなくなったらループを抜ける
}
}
// コミットインターバルに達するか、アイテムがなくなったら、まとめてItemWriterに渡す
itemWriter.write(items);
// ここでトランザクションがコミットされるItemProcessorありの場合:
オプションでItemProcessorを構成して、アイテムをItemWriterに渡す前に処理することも可能です。
List<Object> items = new ArrayList<>(); // 読み込んだアイテムを一時的に保持するリスト
for(int i = 0; i < commitInterval; i++){ // コミットインターバルに達するまでアイテムを読み込む
Object item = itemReader.read(); // ItemReaderから1件読み込み
if (item != null) {
items.add(item); // リストに追加
} else {
break; // 読み込むアイテムがなくなったらループを抜ける
}
}
List<Object> processedItems = new ArrayList<>(); // 処理済みアイテムを一時的に保持するリスト
for(Object item: items){
Object processedItem = itemProcessor.process(item); // ItemProcessorで加工・変換
if (processedItem != null) {
processedItems.add(processedItem); // 処理済みリストに追加
}
}
// コミットインターバルに達するか、アイテムがなくなったら、まとめてItemWriterに渡す
itemWriter.write(processedItems);
// ここでトランザクションがコミットされるChunk指向処理のライフサイクル:
この一連の流れをシーケンス図で表すと以下のようになります。
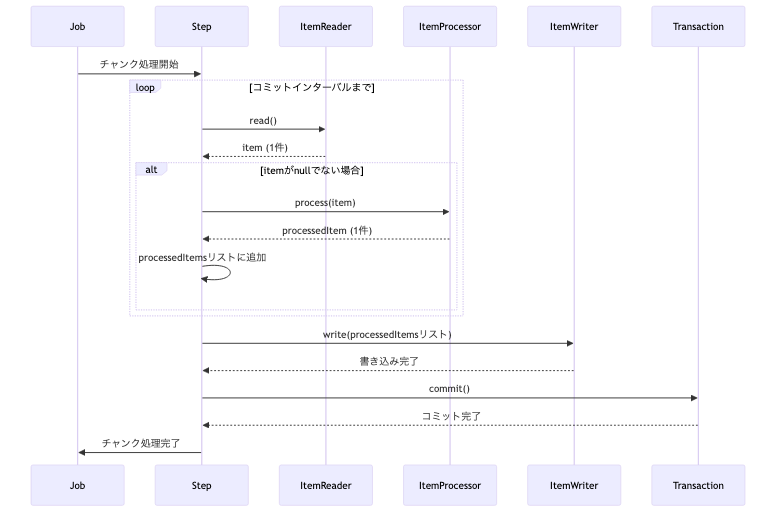
上記のシーケンス図は、Chunk指向処理のライフサイクルを視覚的に示しています。JobからStepが開始され、StepがItemReader、ItemProcessor、ItemWriterをオーケストレーションします。
ItemReaderはデータを1件ずつ読み込み、ItemProcessorはそれを加工します。- これらの処理は、設定された
コミットインターバル(チャンクサイズ)に達するまで繰り返され、処理されたアイテムは一時的にリストに蓄積されます。 コミットインターバルに達すると、蓄積されたアイテムのリストがItemWriterに渡され、一括で書き込み処理が行われます。ItemWriterによる書き込みが完了すると、Transactionがコミットされ、一連の処理が確定します。このトランザクション境界が、Chunk処理の堅牢性と再起動可能性を支える重要な要素となります。
このサイクルを効率的に運用するためには、次項で解説する「チャンクサイズ」や「トランザクション境界」の適切な設定が非常に重要になります。
1-3. コミットインターバル(Chunkサイズ)の具体的な設定方法と考慮事項
コミットインターバル(Chunkサイズ)は、主にStepBuilderのchunk()メソッドを使用して設定します。
Java Configでの設定方法
Spring Batchのジョブ設定をJavaコードで行う場合、StepBuilderのchunk()メソッドに整数値を渡すことでコミットインターバルを設定します。
import org.springframework.batch.core.Step;
import org.springframework.batch.core.repository.JobRepository;
import org.springframework.batch.core.step.builder.StepBuilder;
import org.springframework.batch.item.ItemProcessor;
import org.springframework.batch.item.ItemReader;
import org.springframework.batch.item.ItemWriter;
import org.springframework.transaction.PlatformTransactionManager;
// ... (ItemReader, ItemProcessor, ItemWriterの実装は省略)
@Bean
public Step myChunkStep(
JobRepository jobRepository,
PlatformTransactionManager transactionManager,
ItemReader<String> itemReader,
ItemProcessor<String, String> itemProcessor,
ItemWriter<String> itemWriter) {
return new StepBuilder("myChunkStep", jobRepository)
.<String, String>chunk(10, transactionManager) // ここでコミットインターバルを「10」に設定
.reader(itemReader)
.processor(itemProcessor)
.writer(itemWriter)
.build();
}上記の例では、.<String, String>chunk(10, transactionManager)の部分でコミットインターバルを10に設定しています。
これは、ItemReaderが10件のアイテムを読み込み、ItemProcessorがそれらを処理し、ItemWriterが10件のアイテムをまとめて書き込んだ後にトランザクションがコミットされることを意味します。
transactionManagerは、このチャンク処理のトランザクションを管理するために必要です。
XML設定での設定方法 (Spring Batch 4.x以前のケース)
もしXMLベースのSpring Batch設定を使用している場合、<chunk>タグのcommit-interval属性で設定します。
<job id="myJob">
<step id="myStep">
<tasklet>
<chunk reader="itemReader" processor="itemProcessor" writer="itemWriter" commit-interval="10"/>
</tasklet>
</step>
</job>コミットインターバル(Chunkサイズ)を決定する際の考慮事項
適切なチャンクサイズを設定することは、バッチ処理のパフォーマンスと安定性に大きく影響します。以下の点を考慮して決定してください。
- メモリ使用量:
- チャンクサイズが大きいほど、一度に処理されるアイテム数が増えるため、メモリ使用量が増加します。
- OutOfMemoryErrorを避けるため、システムのメモリ容量と処理対象のアイテムのサイズを考慮して設定します。
- トランザクションオーバーヘッド:
- チャンクサイズが小さいほど、トランザクションのコミット頻度が高くなります。
- トランザクションのコミットにはオーバーヘッドが伴うため、小さすぎると処理全体のパフォーマンスが低下する可能性があります。
- データ量と処理速度:
- 処理対象のデータ量や、
ItemReader、ItemProcessor、ItemWriterの処理速度に応じて調整します。 - 例えば、データベースへの書き込みがボトルネックになる場合、チャンクサイズを大きくすることで、データベースへのアクセス回数を減らし、パフォーマンスを向上できることがあります。
- 処理対象のデータ量や、
- 再起動可能性:
- Spring Batchはチャンク単位でコミットを行うため、処理が失敗した場合でも、最後にコミットされたチャンクの次から処理を再開できます。
- チャンクサイズが大きすぎると、失敗時にロールバックされる範囲が広がり、再処理のコストが高くなる可能性があります。
- ビジネス要件:
- ビジネス上の制約(例: 特定の件数ごとに中間結果を保存する必要がある)がある場合は、それに合わせてチャンクサイズを調整する必要があります。
これらの考慮事項を踏まえ、実際のデータと環境でテストを行いながら最適なチャンクサイズを見つけることが重要です。
最適化のポイント
- トランザクション境界:
- 各チャンクは独立したトランザクションで処理されるため、途中でエラーが発生しても、そのチャンクの処理だけがロールバックされ、再起動時に前回のコミットポイントから再開できます。
コミットインターバル(Chunkサイズ)の具体的な設定方法と考慮事項の具体的な実装コードについては、以下の記事で詳細に解説していますので、是非ご覧ください。
2. Taskletによる非Chunk処理:単一操作のバッチ処理をシンプルに
Spring Batchにおけるバッチ処理の主要なモデルとして、前述の「Chunk指向処理」と、ここで解説する「Tasklet(タスクレット)」があります。
Chunk指向処理が大量のデータを「読み込み(Read)」「処理(Process)」「書き込み(Write)」というチャンク(塊)単位で反復的に処理するのに対し、Taskletは単一のステップで完結する、非アイテム指向の処理に特化しています。
具体的には、以下のようなシナリオでTaskletが非常に有効です。
- ファイルシステム操作:
- ファイルの移動、削除、圧縮、解凍など。
- データベース操作:
- DDL(データ定義言語)の実行(テーブル作成・変更)、ストアドプロシージャの呼び出し、インデックスの再構築など、データそのものの処理ではない操作。
- 外部システム連携:
- 外部APIの呼び出し、メッセージキューへの投入、スクリプトの実行など。
Chunk処理との決定的な違いは、TaskletがItemReader、ItemProcessor、ItemWriterといったコンポーネントを持たず、データアイテムの反復処理を行わない点です。
そのため、Taskletは「非Chunk処理」または「非アイテム指向処理」と呼ばれます。
また、Taskletのexecuteメソッドの各呼び出しは、Spring Batchによってトランザクションでラップされます。
これにより、Tasklet内で発生した処理がアトミックに実行され、エラー発生時には適切にロールバックされるため、堅牢性が保証されます。
2-1. Taskletの処理フロー
Taskletは、org.springframework.batch.core.step.tasklet.Taskletインターフェースを実装して定義します。
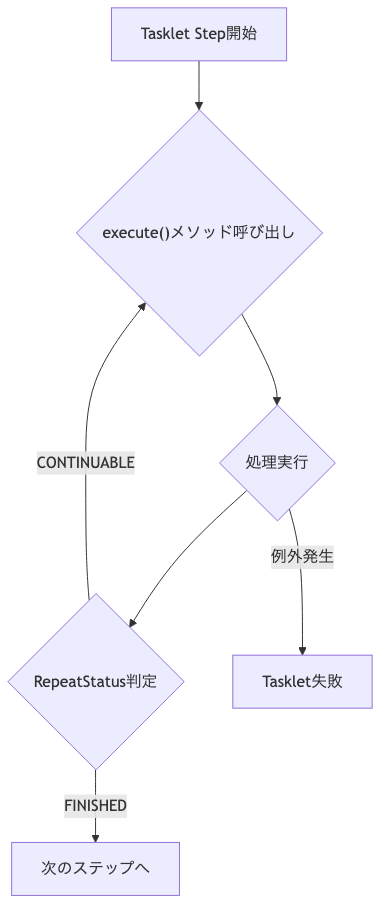
このインターフェースの核となるのがexecuteメソッドです。
Spring Batchは、このexecuteメソッドを呼び出すことでTaskletの処理を実行します。executeメソッドの戻り値であるRepeatStatusによって、ステップの継続か完了かをSpring Batchに伝えます。
RepeatStatus.FINISHEDを返す場合:- Taskletの処理が完了したことを意味し、Spring Batchは次のステップへと進みます。
- 通常、単一のタスクで完結する処理はこの戻り値を使用します。
RepeatStatus.CONTINUABLEを返す場合:- Taskletの処理がまだ継続可能であることを意味し、Spring Batchは
executeメソッドを再度呼び出します。 - これにより、Tasklet自身が内部でループ処理を制御し、例えば外部リソースのポーリングや、一定の条件が満たされるまで処理を繰り返すようなシナリオを実現できます。
- Taskletの処理がまだ継続可能であることを意味し、Spring Batchは
もしexecuteメソッド内で例外がスローされた場合は、そのTaskletの処理は失敗とみなされ、ジョブの失敗として扱われます。
このexecuteメソッドのフロー図を示します。
2-2. Taskletの作成
JavaでTaskletStepを作成するには、StepBuilderのtaskletメソッドにTaskletインターフェースを実装したBeanを渡します。この際、chunkメソッドは呼び出しません。
@Bean
public Step myTaskletStep(JobRepository jobRepository, PlatformTransactionManager transactionManager) {
return new StepBuilder("myTaskletStep", jobRepository)
.tasklet(myCustomTasklet(), transactionManager) // myCustomTaskletはTaskletを実装したBean
.build();
}
// myCustomTaskletの実装例(FileMovingTaskletなど)
// このTaskletはJobParametersからsourcePathとtargetPathを受け取るように設定されます。
// 例: jobParametersBuilder.addString("sourcePath", "/path/to/source.txt");
// jobParametersBuilder.addString("targetPath", "/path/to/target/");以下に、ファイル移動を行うTaskletの具体的な例を示します。
// 例: ファイルを移動するTasklet
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.springframework.batch.core.StepContribution;
import org.springframework.batch.core.scope.context.ChunkContext;
import org.springframework.batch.core.step.tasklet.Tasklet;
import org.springframework.batch.repeat.RepeatStatus;
import org.springframework.beans.factory.InitializingBean;
import org.springframework.util.Assert;
import java.io.File;
import java.nio.file.Files;
import java.nio.file.Path;
import java.nio.file.Paths;
import java.nio.file.StandardCopyOption;
public class FileMovingTasklet implements Tasklet, InitializingBean {
private static final Logger logger = LoggerFactory.getLogger(FileMovingTasklet.class);
private String sourcePath;
private String targetPath;
// JobParametersからパスを受け取るためのセッター
public void setSourcePath(String sourcePath) {
this.sourcePath = sourcePath;
}
public void setTargetPath(String targetPath) {
this.targetPath = targetPath;
}
@Override
public RepeatStatus execute(StepContribution contribution, ChunkContext chunkContext) throws Exception {
Path source = Paths.get(sourcePath);
Path target = Paths.get(targetPath);
if (!Files.exists(source)) {
logger.warn("Source file does not exist: {}", sourcePath);
// ファイルが存在しない場合はスキップまたはエラーとして処理
// ここではFINISHEDを返してステップを完了させるが、要件に応じて例外をスローすることも可能
return RepeatStatus.FINISHED;
}
try {
Files.move(source, target.resolve(source.getFileName()), StandardCopyOption.REPLACE_EXISTING);
logger.info("Successfully moved file from {} to {}", sourcePath, target.resolve(source.getFileName()));
} catch (Exception e) {
logger.error("Failed to move file from {} to {}: {}", sourcePath, target.resolve(source.getFileName()), e.getMessage());
throw e; // エラーを再スローしてステップを失敗させる
}
return RepeatStatus.FINISHED;
}
@Override
public void afterPropertiesSet() throws Exception {
Assert.notNull(sourcePath, "sourcePath must be set");
Assert.notNull(targetPath, "targetPath must be set");
}
}Taskletはシンプルながらも、バッチ処理の前後処理や、特定のビジネスロジックの実行など、幅広い用途で活用できます。
Taskletの具体的な活用方法と実装コードについては、以下の記事で詳細に解説していますので、是非ご覧ください。
2-3. TaskletAdapterによる既存クラスの活用
Spring Batchでは、TaskletAdapterを使用することで、既存の任意のクラスのメソッドをTaskletとして適応させることができます。これは、例えば以下のような既存のビジネスロジックをTaskletとしてバッチ処理に組み込みたい場合に非常に有用です。
- サービス層のメソッド:
- 複雑なビジネスロジックが実装されたサービスメソッドをバッチ処理の一部として実行したい場合。
- リポジトリ/DAOの更新メソッド:
- 特定の条件に基づいてデータベースのレコードを一括更新するメソッドなど。
- 外部連携処理:
- 既存の外部システム連携用のクライアントメソッドなど。
Taskletインターフェースを直接実装することなく、既存のビジネスロジックを再利用できるため、開発効率の向上に貢献します。
Spring Batchが提供する主なTaskletAdapterには、MethodInvokingTaskletAdapterの他に、CallableTaskletAdapterやRunnableTaskletAdapterなどがあります。
これらを適切に使い分けることで、様々な既存の処理を柔軟にバッチステップとして組み込むことが可能です。
@Bean
public MethodInvokingTaskletAdapter myDaoTasklet() {
MethodInvokingTaskletAdapter adapter = new MethodInvokingTaskletAdapter();
adapter.setTargetObject(myExistingDao()); // 既存のDAO Bean
adapter.setTargetMethod("updateStatus"); // DAOのメソッド名
return adapter;
}
// myExistingDaoは既存のDAOクラスのBeanを想定
// @Bean
// public MyExistingDao myExistingDao() {
// return new MyExistingDao();
// }TaskletAdapterの具体的な活用方法と実装コードについては、以下の記事で詳細に解説していますので、是非ご覧ください。
3. Flow, Split, Deciderによるジョブフロー制御:複雑なバッチ処理のオーケストレーション
実際のビジネス要件では、バッチ処理は単一のステップで完結することは稀です。
複数のステップを連携させ、条件に応じて処理を分岐させたり、複数の処理を並行して実行したりするなど、複雑なフロー制御が求められます。
Spring Batchは、このような複雑なジョブフローを柔軟かつ宣言的に定義するための強力な機能として、Flow、Split、Deciderを提供します。
これらの機能を活用することで、バッチ処理のロジックを明確にし、再利用性や保守性を高めることができます。
- Flow (フロー):
- 複数のステップや他のフローをまとめた論理的な単位です。再利用可能なサブフローを定義する際に役立ちます。
- Split (スプリット):
- 複数のフローを並行して実行するための機能です。処理時間を短縮したい場合に利用します。
- Decider (デサイダー):
- ステップの実行結果に基づいて、次にどのステップやフローに進むかをプログラム的に決定するためのコンポーネントです。複雑な条件分岐を実装する際に使用します。
これらの要素を組み合わせることで、ビジネスロジックに即した柔軟なバッチ処理のオーケストレーションが可能になります。
3-1. 順次フロー (Sequential Flow)
最も基本的なジョブフローは、ステップを順番に実行する順次フローです。next()メソッドを使用して、次のステップを指定します。
// 例: 順次フロー
@Bean
public Job sequentialJob(JobRepository jobRepository, PlatformTransactionManager transactionManager) {
return new JobBuilder("sequentialJob", jobRepository)
.start(step1(jobRepository, transactionManager))
.next(step2(jobRepository, transactionManager))
.next(step3(jobRepository, transactionManager))
.end()
.build();
}3-2. 条件付きフロー (Conditional Flow)
バッチ処理の実行中に、特定の条件に基づいて処理の流れを分岐させたい場合があります。Spring Batchでは、on()、to()、from()メソッドを組み合わせて条件付きフローを定義します。
on(String pattern):- 直前のステップまたは
DeciderのExitStatus(終了ステータス)が指定されたパターンに一致した場合に、次の遷移を定義します。
- 直前のステップまたは
to(Step step):on()で指定された条件が満たされた場合に実行するステップを指定します。
from(Step step):- 別のステップから開始する条件付きフローを定義します。
ここで重要なのは、Spring Batchにおける ExitStatusとFlowStatusの役割です。
ExitStatus:- ステップの実行結果を示す文字列です。
COMPLETED、FAILEDなどが標準で用意されており、ステップのStepExecutionに設定されます。 on()メソッドはこのExitStatusを評価して次の遷移を決定します。
- ステップの実行結果を示す文字列です。
FlowStatus:JobExecutionDeciderが返すステータスで、ジョブフロー全体の進行を制御するために使用されます。FlowStatusはExitStatusと同様に文字列ベースですが、Deciderがフローの分岐を決定するために特化しています。
JobExecutionDeciderを実装することで、より複雑なビジネスロジックに基づいてプログラム的にフローを決定できます。
// 例: Deciderを使った条件分岐(ファイル存在チェック)
@Bean
public Job conditionalJob(JobRepository jobRepository, PlatformTransactionManager transactionManager) {
return new JobBuilder("conditionalJob", jobRepository)
.start(step1(jobRepository, transactionManager)) // 最初のステップ
.next(fileCheckDecider()) // ファイル存在チェックを行うDeciderを挟む
.on("FILE_EXISTS") // Deciderの結果が"FILE_EXISTS"の場合
.to(processFileStep(jobRepository, transactionManager)) // ファイル処理ステップへ
.from(fileCheckDecider()) // Deciderの結果が別のパスの場合
.on("NO_FILE") // "NO_FILE"の場合
.to(logNoFileStep(jobRepository, transactionManager)) // ファイルなしログステップへ
.end() // フローの終了
.build();
}
@Bean
public JobExecutionDecider fileCheckDecider() {
return new FileExistenceDecider();
}
// ファイルの存在をチェックするDeciderの実装例
public class FileExistenceDecider implements JobExecutionDecider {
private static final Logger logger = LoggerFactory.getLogger(FileExistenceDecider.class);
@Override
public FlowStatus decide(JobExecution jobExecution, StepExecution stepExecution) {
// JobParametersからチェック対象のファイルパスを取得
String filePath = jobExecution.getJobParameters().getString("inputFilePath");
if (filePath == null) {
logger.error("inputFilePath JobParameter is not set.");
return new FlowStatus("FAILED"); // パラメータがない場合は失敗
}
File file = new File(filePath);
if (file.exists() && file.isFile()) {
logger.info("File exists: {}", filePath);
return new FlowStatus("FILE_EXISTS"); // ファイルが存在する場合
} else {
logger.info("File does not exist: {}", filePath);
return new FlowStatus("NO_FILE"); // ファイルが存在しない場合
}
}
}
// ファイル処理ステップの例
@Bean
public Step processFileStep(JobRepository jobRepository, PlatformTransactionManager transactionManager) {
return new StepBuilder("processFileStep", jobRepository)
.tasklet((contribution, chunkContext) -> {
logger.info("Processing file...");
// ここにファイル処理ロジックを記述
return RepeatStatus.FINISHED;
}, transactionManager)
.build();
}
// ファイルなしログステップの例
@Bean
public Step logNoFileStep(JobRepository jobRepository, PlatformTransactionManager transactionManager) {
return new StepBuilder("logNoFileStep", jobRepository)
.tasklet((contribution, chunkContext) -> {
logger.info("No input file found. Skipping file processing.");
// ここにファイルがない場合のログ出力や後処理ロジックを記述
return RepeatStatus.FINISHED;
}, transactionManager)
.build();
}3-3. 並行フロー (Split Flows)
複数の独立した処理を並行して実行することで、バッチ処理全体の実行時間を短縮できます。
Spring BatchのSplit機能は、複数のFlowを並行して実行することを可能にします。
split()メソッドには、並行実行のためのTaskExecutorを指定します。TaskExecutorは、タスクをどのように実行するかをSpringに伝えるインターフェースです。
SimpleAsyncTaskExecutor:- デフォルトで新しいスレッドを生成してタスクを実行します。
- 開発環境での簡単な並行処理には便利ですが、スレッドの生成コストが高く、本番環境での大量のタスク実行には不向きです。
ThreadPoolTaskExecutor:- スレッドプールを使用してタスクを実行します。
- スレッドの再利用によりオーバーヘッドを削減し、スレッド数の上限を設定することでシステムリソースの枯渇を防ぎます。
- 本番環境での並行処理にはこちらが推奨されます。
並行フローを利用する際の注意点としては、各フローが独立していることを確認すること、リソースの競合が発生しないように適切に同期を取ること、エラーハンドリングを考慮することなどが挙げられます。
// 例: Splitを使った並行フロー
@Bean
public Job splitJob(JobRepository jobRepository, PlatformTransactionManager transactionManager) {
Flow flow1 = new FlowBuilder<Flow>("flow1")
.start(stepA(jobRepository, transactionManager))
.build();
Flow flow2 = new FlowBuilder<Flow>("flow2")
.start(stepB(jobRepository, transactionManager))
.next(stepC(jobRepository, transactionManager))
.build();
// 本番環境ではThreadPoolTaskExecutorの使用を推奨
ThreadPoolTaskExecutor taskExecutor = new ThreadPoolTaskExecutor();
taskExecutor.setCorePoolSize(5); // コアとなるスレッド数
taskExecutor.setMaxPoolSize(10); // 最大スレッド数
taskExecutor.setQueueCapacity(25); // キューの容量
taskExecutor.setThreadNamePrefix("batch-split-");
taskExecutor.initialize();
return new JobBuilder("splitJob", jobRepository)
.start(stepStart(jobRepository, transactionManager))
.split(taskExecutor) // ThreadPoolTaskExecutorを指定
.add(flow1, flow2)
.end()
.build();
}3-4. Deciderによるプログラム的フロー決定
JobExecutionDeciderインターフェースは、Spring Batchのジョブフローにおいて、ステップの実行結果だけでなく、より複雑なビジネスロジックに基づいて次に実行するステップやフローをプログラム的に決定するための強力なメカニズムを提供します。
例えば、以下のようなシナリオでDeciderが活用できます。
- 複数条件の組み合わせ:
- 複数の
JobParametersやJobExecutionContext内の情報、外部システムの状態などを組み合わせて複雑な条件を判定し、フローを分岐させる。
- 複数の
- 動的なフロー制御:
- 実行時のデータ量や処理結果に応じて、後続のステップをスキップしたり、異なる処理パスを選択したりする。
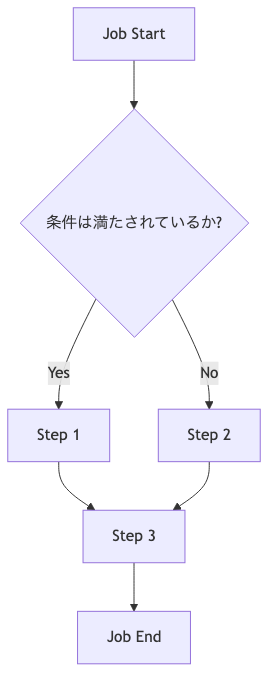
上記のシーケンス図が示すように、Deciderはジョブフローの途中に配置され、そのdecideメソッドの戻り値であるFlowStatusに基づいて、次にどのパスに進むべきかをSpring Batchに指示します。
これにより、静的なフロー定義だけでは実現が難しい、柔軟で動的なジョブフローを構築することが可能になります。
3-5. ジョブの終了ステータス制御
Spring Batchでは、ジョブの実行結果に応じて、end()、fail()、stopAndRestart()といったメソッドを使用して、ジョブの終了ステータスを明示的に制御できます。これにより、後続のジョブの起動や運用監視システムとの連携を柔軟に行うことが可能になります。
end():- ジョブを正常終了させます。
ExitStatus.COMPLETEDとして終了します。
fail():- ジョブを異常終了させます。
ExitStatus.FAILEDとして終了し、通常は再起動不可能な状態となります。
stopAndRestart():- ジョブを停止し、再起動可能な状態にします。
ExitStatus.STOPPEDとして終了し、同じJobParametersで再度ジョブを実行すると、停止したステップから処理を再開できます。
また、ExitStatusは文字列であるため、標準で用意されているもの以外に、独自のカスタムExitStatusを定義して、より詳細なジョブの終了理由を表現することも可能です。
これは、複雑なジョブフローにおける条件分岐や、運用時のトラブルシューティングに役立ちます。
以下に、ジョブの終了ステータスを制御するサンプルコードを示します。stepAでは、JobParametersの値に基づいて、意図的に成功、失敗、または停止のExitStatusを設定する例を示します。
// 例: ジョブの終了ステータス制御
@Bean
public Job statusControlJob(JobRepository jobRepository, PlatformTransactionManager transactionManager) {
return new JobBuilder("statusControlJob", jobRepository)
.start(stepA(jobRepository, transactionManager))
.on("COMPLETED").to(stepB(jobRepository, transactionManager)) // stepAがCOMPLETEDならstepBへ
.on("FAILED").fail() // stepAがFAILEDならジョブを異常終了
.from(stepB(jobRepository, transactionManager))
.on("COMPLETED").end() // stepBがCOMPLETEDならジョブを正常終了
.on("STOPPED").stopAndRestart(stepC(jobRepository, transactionManager)) // stepBがSTOPPEDならstepCから再開可能に
.end() // その他の場合は正常終了
.build();
}
// 各ステップの定義は省略
@Bean
public Step stepA(JobRepository jobRepository, PlatformTransactionManager transactionManager) {
return new StepBuilder("stepA", jobRepository)
.tasklet((contribution, chunkContext) -> {
String outcome = chunkContext.getStepContext().getJobParameters().getString("stepAOutcome");
System.out.println("Step A executed with outcome: " + outcome);
if ("FAIL".equals(outcome)) {
throw new RuntimeException("Simulated failure in Step A based on JobParameter.");
} else if ("STOP".equals(outcome)) {
contribution.getStepExecution().setExitStatus(new ExitStatus("STOPPED"));
}
// "COMPLETED" または他の値の場合はデフォルトでFINISHEDを返す
return RepeatStatus.FINISHED;
}, transactionManager)
.build();
}
@Bean
public Step stepB(JobRepository jobRepository, PlatformTransactionManager transactionManager) {
return new StepBuilder("stepB", jobRepository)
.tasklet((contribution, chunkContext) -> {
System.out.println("Step B executed.");
return RepeatStatus.FINISHED;
}, transactionManager)
.build();
}
@Bean
public Step stepC(JobRepository jobRepository, PlatformTransactionManager transactionManager) {
return new StepBuilder("stepC", jobRepository)
.tasklet((contribution, chunkContext) -> {
System.out.println("Step C executed (after restart).");
return RepeatStatus.FINISHED;
}, transactionManager)
.build();
}ジョブフロー制御の具体的な活用方法と実装コードについては、以下の記事で詳細に解説していますので、是非ご覧ください。
まとめ
本記事では、Spring Batchの基本的な処理モデルであるChunk指向処理とTasklet、そして複雑なジョブフローを制御するためのFlow、Split、Deciderについて解説しました。
- Chunk指向処理: 大量データを効率的に処理するためのRead-Process-Writeモデル。適切なチャンクサイズとトランザクション境界の理解が重要です。
- Tasklet: ファイル操作やDBのDDL実行など、単一の操作で完結する処理に適しています。既存のビジネスロジックを
TaskletAdapterで再利用することも可能です。 - ジョブフロー制御:
next()による順次フロー、on()/to()/from()とDeciderによる条件付きフロー、Splitによる並行フローを活用することで、複雑なバッチ処理のロジックを柔軟に構築できます。
これらの機能を理解し、適切に使い分けることで、Spring Batchを使ったバッチ処理の設計・実装がより効率的かつ堅牢になります。次の記事では、バッチ処理の堅牢性をさらに高めるためのエラーハンドリングと再起動戦略について深く掘り下げていきます。
免責事項
本記事の内容は、執筆時点での情報に基づいており、その正確性、完全性、有用性を保証するものではありません。
記事の内容は、技術の進歩や環境の変化により、予告なく変更される可能性があります。
本記事の情報を利用したことにより生じた、いかなる損害についても、筆者および公開元は一切の責任を負いません。
ご自身の判断と責任において、本記事の情報をご活用ください。