
堅牢なバッチ処理のための設計パターン
「バッチ処理が途中で失敗したらどうする?」
「エラーが発生しても処理を止めずに続けたい」
「再実行したときに、最初からやり直すのは避けたい」
バッチ処理を運用する上で、エラーへの対応と再起動可能性は避けて通れない重要な課題です。
バッチ処理は、一度実行したら終わりではなく、エラー発生時のリカバリや再実行が考慮される必要があります。
本記事では、Spring Batchが提供する強力なエラーハンドリング機能(リトライ、スキップ)と、バッチ処理の信頼性を高めるための再起動可能性、そして冪等性の確保について、具体的なコード例を交えながら堅牢なバッチ処理を実現するための設計パターンを解説します。
これらの設計パターンを習得し、どんな状況でも安定して動作する堅牢なバッチ処理を構築しましょう。
目次
- 1. エラーハンドリングとリトライ戦略
- 1-1. Spring Batchのリトライ設定とSpring Retryの関係性
- 1-2. Spring Retryの主要な概念
- 1.
@Retryableアノテーションによる宣言的リトライ - 2.
RetryTemplateによるプログラム的リトライ - 3.
RetryPolicyとBackoffPolicy - 4.
RecoveryCallback - 5. Spring Batch Step Configurationの関係性
- 1.
- 2. スキップとリスナーの活用
- 2-1. スキップ機能による耐障害性の向上
- スキップ機能の基本設定
- スキップ対象の例外の制御
- スキップの注意点
- 2-2. リスナーを活用した処理の監視と拡張
- リスナーの種類と役割
SkipListenerの実装例- リスナーの登録方法
SkipListenerとトランザクション
- 2-1. スキップ機能による耐障害性の向上
- 3. 再起動可能性と冪等性の確保
- 3-1. 再起動可能性 (Restartability) とは
- なぜ再起動可能性が重要なのか?
- Spring Batchでの実現方法
- 注意点
- 3-2. 冪等性 (Idempotency) とは
- なぜ冪等性が重要なのか?
- Spring Batchでの実現方法(開発者が考慮すべき点)
- 具体例
- 3-3. 再起動可能性と冪等性の組み合わせ
- 3-1. 再起動可能性 (Restartability) とは
- まとめ
対象読者
- Spring Batchを利用して堅牢なバッチ処理を構築したい開発者
- エラーハンドリング、リトライ、スキップ、再起動戦略について学びたいエンジニア
- バッチ処理の信頼性と運用性を向上させたいと考えている方
1. エラーハンドリングとリトライ戦略
バッチ処理中に発生する一時的なエラー(DBコネクションの一時的な切断、ネットワークの一時的な障害、デッドロックなど)に対しては、自動的なリトライが非常に有効です。
Spring Batchは、このような一時的な失敗から処理をより堅牢にするために、内部的にSpring Retryライブラリを統合してリトライ機能を提供しています。
Spring Batch 2.2.0以降、リトライ機能は独立したライブラリであるSpring Retryに分離されましたが、Spring Batchは引き続きこのライブラリを利用してリトライ処理を自動化しています。
これにより、開発者は宣言的にリトライを設定するだけで、複雑なリトライロジックを実装する必要がありません。
また、リトライしても解決しないエラーや、ビジネスロジック上のエラーに対しては、適切なエラーハンドリング(ログ出力、通知、エラーデータの隔離など)が必要です。
1-1. Spring Batchのリトライ設定とSpring Retryの関係性
Spring Batchは、以下のように宣言的にStepレベルのリトライを設定できます。
// 例: リトライ設定
@Bean
public Step myStep(JobRepository jobRepository, PlatformTransactionManager transactionManager,
ItemReader<String> reader, ItemProcessor<String, String> processor, ItemWriter<String> writer) {
return new StepBuilder("myStep", jobRepository)
.<String, String>chunk(10, transactionManager)
.reader(reader)
.processor(processor)
.writer(writer)
.faultTolerant() // フォールトトレラントを有効化
.retryLimit(3) // 3回までリトライ
.retry(DeadlockLoserDataAccessException.class) // 特定の例外でリトライ
.build();
}Spring BatchのStepBuilderで設定するリトライ機能(faultTolerant()、retryLimit()、retry())は、内部的にSpring Retryライブラリの機能を利用しています。
faultTolerant():- このメソッドを呼び出すことで、Stepレベルでのフォールトトレランス(耐障害性)が有効になり、リトライ機能がアクティブになります。
retryLimit(int limit):- これはSpring Retryの
RetryPolicyにおける最大試行回数(maxAttempts)に相当します。指定された回数だけ処理を再試行します。
- これはSpring Retryの
retry(Class<? extends Throwable>... classes):- これはSpring Retryの
RetryPolicyにおいて、リトライの対象となる例外クラスを指定することに相当します。 - ここで指定された例外が発生した場合にのみリトライが実行されます。
- これはSpring Retryの
このように、Spring BatchのStep設定は、Spring Retryの強力な機能を抽象化し、バッチ処理のコンテキストで簡単に利用できるようにしています。
1-2. Spring Retryの主要な概念
Spring Batchのリトライ機能の背後にあるSpring Retryライブラリは、より柔軟で強力なリトライメカニズムを提供します。
ここでは、初心者が理解しておくと役立つ主要な概念をいくつか紹介します。
1. @Retryableアノテーションによる宣言的リトライ
@Retryableアノテーションを使用すると、メソッドレベルで宣言的にリトライ動作を定義できます。これは、Spring BatchのItemProcessorやItemWriter内で呼び出されるビジネスロジックに適用すると特に効果的です。
import org.springframework.retry.annotation.Backoff;
import org.springframework.retry.annotation.Recover;
import org.springframework.retry.annotation.Retryable;
import org.springframework.stereotype.Service;
@Service
public class MyService {
private int counter = 0;
@Retryable(
value = {RuntimeException.class}, // リトライ対象の例外
maxAttempts = 3, // 最大リトライ回数
backoff = @Backoff(delay = 1000) // リトライ間の待機時間(ミリ秒)
)
public String unreliableMethod() {
counter++;
System.out.println("Attempt " + counter + ": Calling unreliable method...");
if (counter < 3) {
throw new RuntimeException("Simulated network error!");
}
System.out.println("Attempt " + counter + ": Method succeeded!");
counter = 0; // リセット
return "Success";
}
@Recover
public String recover(RuntimeException e) {
System.err.println("Recovering from: " + e.getMessage());
counter = 0; // リセット
return "Fallback value";
}
}上記の例では、unreliableMethodがRuntimeExceptionをスローした場合、最大3回まで1秒間隔でリトライされます。全てのリトライが失敗した場合は、@Recoverアノテーションが付与されたrecoverメソッドが呼び出され、フォールバック処理が実行されます。
2. RetryTemplateによるプログラム的リトライ
より複雑なリトライロジックや、アノテーションベースのリトライが適用できないシナリオでは、RetryTemplateをプログラム的に使用できます。
RetryTemplateは、RetryPolicyとBackoffPolicyを組み合わせてリトライ動作を制御します。
import org.springframework.retry.RetryCallback;
import org.springframework.retry.RetryContext;
import org.springframework.retry.support.RetryTemplate;
import org.springframework.retry.policy.SimpleRetryPolicy;
import org.springframework.retry.backoff.FixedBackOffPolicy;
public class MyRetryProcessor {
public String processWithRetry() {
RetryTemplate retryTemplate = new RetryTemplate();
// リトライポリシーの設定: 最大3回リトライ
SimpleRetryPolicy retryPolicy = new SimpleRetryPolicy();
retryPolicy.setMaxAttempts(3);
retryTemplate.setRetryPolicy(retryPolicy);
// バックオフポリシーの設定: 1秒間隔でリトライ
FixedBackOffPolicy backOffPolicy = new FixedBackOffPolicy();
backOffPolicy.setBackOffPeriod(1000L);
retryTemplate.setBackOffPolicy(backOffPolicy);
try {
return retryTemplate.execute(new RetryCallback<String, RuntimeException>() {
private int attempt = 0;
@Override
public String doWithRetry(RetryContext context) throws RuntimeException {
attempt++;
System.out.println("RetryTemplate Attempt " + attempt + ": Executing task...");
if (attempt < 3) {
throw new RuntimeException("Simulated transient error!");
}
return "RetryTemplate Success";
}
});
} catch (RuntimeException e) {
System.err.println("RetryTemplate failed after all attempts: " + e.getMessage());
return "RetryTemplate Fallback";
}
}
}3. RetryPolicyとBackoffPolicy
RetryPolicy:- どの例外でリトライするか、最大何回リトライするかなど、リトライの条件を定義します。Spring Batchの
retry()やretryLimit()は、このRetryPolicyの概念に基づいています。
- どの例外でリトライするか、最大何回リトライするかなど、リトライの条件を定義します。Spring Batchの
BackoffPolicy:- リトライ間の待機時間を定義します。固定時間待機する
FixedBackOffPolicyや、指数関数的に待機時間を増やすExponentialBackOffPolicyなどがあります。
- リトライ間の待機時間を定義します。固定時間待機する
4. RecoveryCallback
全てのリトライ試行が失敗した場合に実行されるフォールバック処理を定義します。@RecoverアノテーションやRetryTemplateのrecoverメソッドで指定できます。
これにより、一時的なエラーが解決しなかった場合でも、アプリケーションが適切に回復処理を行えるようになります。
5. Spring Batch Step Configurationの関係性
@RetryableアノテーションやRetryTemplateは、Spring BatchのStepの内部、例えばItemProcessorやItemWriterで呼び出される個別のビジネスロジックに対して、よりきめ細やかなリトライ制御を適用したい場合に直接使用します。
RecoveryCallbackは、これらのリトライが全て失敗した場合のフォールバック処理を定義するもので、Spring BatchのStepレベルのエラーハンドリングと連携して、より堅牢なバッチ処理を実現します。
この関係性を図で示すと以下のようになります。
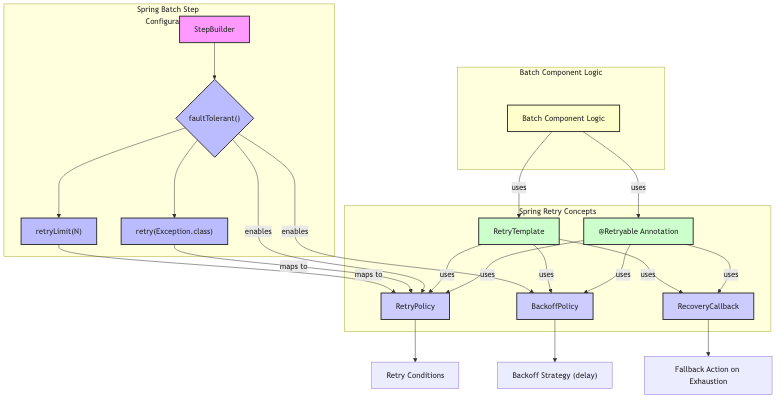
Spring Batchリトライ戦略の具体的なハンズオンについては、以下の記事で詳細に解説していますので、是非ご覧ください。
2. スキップとリスナーの活用
不正なデータや処理できないデータが混入している場合、バッチ処理全体を停止させるのではなく、そのデータだけをスキップして処理を続行したいことがあります。
Spring Batchは、skip 機能と Listener を使ってこれを実現します。
2-1. スキップ機能による耐障害性の向上
バッチ処理において、一部の不正なデータや予期せぬエラーによって処理全体が停止してしまうのは避けたい状況です。
Spring Batchのスキップ機能は、このような問題が発生した場合でも、特定のアイテムをスキップして処理を続行し、バッチジョブの耐障害性を高めるための強力なメカニズムを提供します。
スキップ機能の基本設定
スキップ機能を有効にするには、StepBuilderでfaultTolerant()メソッドを呼び出し、その後にスキップに関する設定を行います。
// 例: スキップ設定
@Bean
public Step skipStep(JobRepository jobRepository, PlatformTransactionManager transactionManager,
ItemReader<String> reader, ItemProcessor<String, String> processor, ItemWriter<String> writer) {
return new StepBuilder("skipStep", jobRepository)
.<String, String>chunk(10, transactionManager)
.reader(reader)
.processor(processor)
.writer(writer)
.faultTolerant() // 耐障害性を有効にする
.skipLimit(10) // 10件までスキップを許容
.skip(FlatFileParseException.class) // FlatFileParseException発生時にスキップ
.listener(new MySkipListener()) // スキップされたアイテムをログに出力するリスナー
.build();
}上記の例では、以下の設定を行っています。
faultTolerant(): このStepで耐障害性(スキップやリトライなど)を有効にすることを示します。skipLimit(10): Step全体で最大10件のアイテムスキップを許容します。この制限に達すると、それ以降のスキップ対象例外が発生した場合、Stepは失敗します。skip(FlatFileParseException.class):FlatFileParseExceptionが発生した場合に、そのアイテムをスキップ対象とします。指定された例外クラスとそのサブクラスがスキップされます。
スキップ対象の例外の制御
特定の例外のみをスキップ対象とし、それ以外の例外ではStepを失敗させたい場合や、逆に特定の例外だけはスキップせずStepを失敗させたい場合があります。
- すべての例外をスキップし、特定の例外のみ失敗させる:
skip(Exception.class)で全ての例外をスキップ対象とし、noSkip(SpecificException.class)で特定の例外をスキップ対象から除外できます。除外された例外が発生した場合、Stepは失敗します。
@Bean
public Step step1(JobRepository jobRepository, PlatformTransactionManager transactionManager) {
return new StepBuilder("step1", jobRepository)
.<String, String>chunk(10, transactionManager)
.reader(flatFileItemReader())
.writer(itemWriter())
.faultTolerant()
.skipLimit(10)
.skip(Exception.class) // すべての例外をスキップ対象とする
.noSkip(FileNotFoundException.class) // FileNotFoundExceptionはスキップせず、Stepを失敗させる
.build();
}スキップの注意点
skipLimitは、Read、Process、Writeのどのフェーズで発生したスキップも合計してカウントされます。skipLimitに設定した値は、許容するスキップの「最大数」です。例えばskipLimit(10)の場合、11回目のスキップ対象例外が発生した時点でStepは失敗します。skip()で指定されていない例外や、noSkip()で除外された例外は、Stepを致命的に失敗させます。
2-2. リスナーを活用した処理の監視と拡張
Spring Batchのリスナーは、バッチ処理の様々なライフサイクルイベント(ジョブの開始/終了、ステップの開始/終了、アイテムの読み込み/処理/書き込みなど)に介入し、カスタムロジックを実行するためのメカニズムです。
これにより、処理の監視、ログ記録、メトリクス収集、エラー通知、リソースのクリーンアップなど、多岐にわたる要件に対応できます。
リスナーの種類と役割
Spring Batchには、様々な粒度でイベントを捕捉するためのリスナーインターフェースが用意されています。
StepExecutionListener:- Stepの実行前(
beforeStep)と実行後(afterStep)に呼び出されます。afterStepではExitStatusをカスタマイズすることも可能です。 - 対応アノテーション:
@BeforeStep,@AfterStep
- Stepの実行前(
ChunkListener:- チャンク処理の開始前(
beforeChunk)、成功後(afterChunk)、エラー発生後(afterChunkError)に呼び出されます。トランザクションの開始後、アイテムの読み込み前にbeforeChunkが呼ばれます。 - 対応アノテーション:
@BeforeChunk,@AfterChunk,@AfterChunkError
- チャンク処理の開始前(
ItemReadListener<T>:ItemReaderによるアイテム読み込みの直前(beforeRead)、成功後(afterRead)、エラー発生時(onReadError)に呼び出されます。onReadErrorでは発生した例外を捕捉し、ログ記録などに利用できます。- 対応アノテーション:
@BeforeRead,@AfterRead,@OnReadError
ItemProcessListener<T, S>:ItemProcessorによるアイテム処理の直前(beforeProcess)、成功後(afterProcess)、エラー発生時(onProcessError)に呼び出されます。- 対応アノテーション:
@BeforeProcess,@AfterProcess,@OnProcessError
ItemWriteListener<S>:ItemWriterによるアイテム書き込みの直前(beforeWrite)、成功後(afterWrite)、エラー発生時(onWriteError)に呼び出されます。- 対応アノテーション:
@BeforeWrite,@AfterWrite,@OnWriteError
SkipListener<T, S>:- スキップ機能と連携し、実際にアイテムがスキップされた際に呼び出される特別なリスナーです。
ItemReadListenerなどのon*Errorメソッドはエラー発生時に呼び出されますが、必ずしもスキップを意味しません(リトライ後に成功する可能性もあるため)。SkipListenerは、読み込み時(onSkipInRead)、処理時(onSkipInProcess)、書き込み時(onSkipInWrite)にアイテムがスキップされたことを正確に通知します。
SkipListenerの実装例
スキップされたアイテムの詳細をログに出力するSkipListenerの例です。
public class MySkipListener implements SkipListener<String, String> {
@Override
public void onSkipInRead(Throwable t) {
System.err.println("Read skipped: " + t.getMessage());
}
@Override
public void onSkipInProcess(String item, Throwable t) {
System.err.println("Process skipped: item=" + item + ", error=" + t.getMessage());
}
@Override
public void onSkipInWrite(String item, Throwable t) {
System.err.println("Write skipped: item=" + item + ", error=" + t.getMessage());
}
}リスナーの登録方法
リスナーは、StepBuilderのlistener()メソッドを使って登録できます。
return new StepBuilder("skipStep", jobRepository)
// ...
.listener(new MySkipListener()) // スキップされたアイテムをログに出力するリスナー
.build();また、@BeforeStepや@OnSkipInReadのようなアノテーションをPOJOのメソッドに付与することで、Spring Batchが自動的に対応するリスナーとして認識し、登録することも可能です。
SkipListenerとトランザクション
SkipListenerは、Spring Batchの堅牢なエラーハンドリングにおいて重要な役割を果たします。
特に、トランザクションとの連携は、スキップされたアイテムの処理を安全かつ確実に実行するために理解しておくべき重要なポイントです。
1. SkipListenerの呼び出しタイミングとトランザクション境界
SkipListenerの各メソッド(onSkipInRead, onSkipInProcess, onSkipInWrite)は、関連するトランザクションがコミットされる直前に呼び出されます。このタイミングは非常に重要であり、以下の目的があります。
- トランザクションの独立性:
SkipListener内で実行される処理(例: スキップされたアイテムのログ記録や別のテーブルへの移動)が、メインのバッチ処理のトランザクションのロールバックによって影響を受けないように保護されます。
- データの一貫性:
- スキップされたアイテムに関する情報が、チャンク全体の処理が成功し、トランザクションがコミットされる直前に記録されるため、データの一貫性が保たれます。
図: SkipListenerとトランザクションのライフサイクル
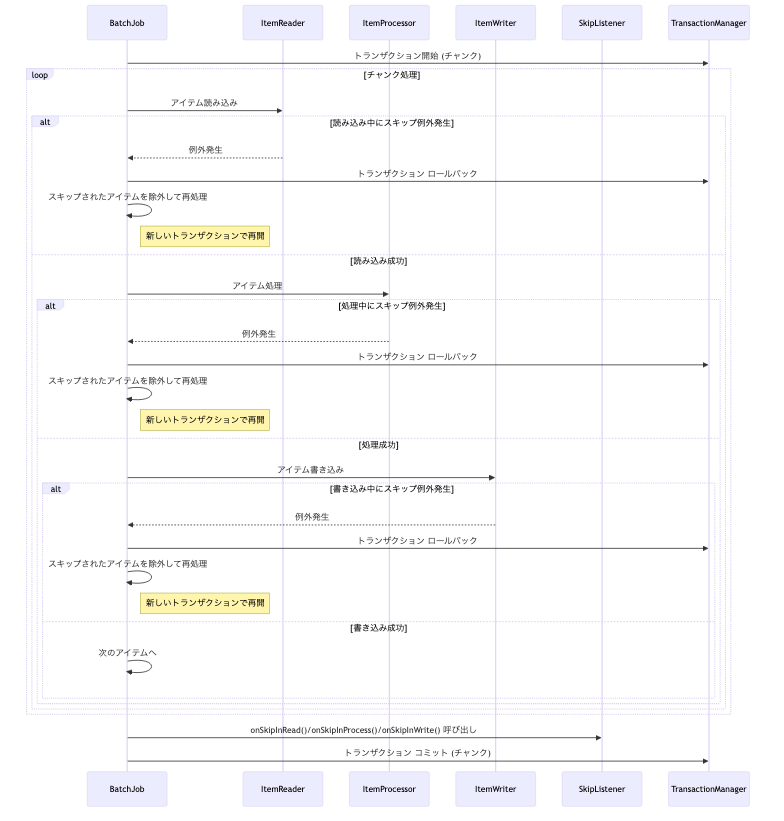
2. 各onSkipメソッドとトランザクションの関係
onSkipInRead(Throwable t):ItemReaderでスキップ可能な例外が発生した場合に呼び出されます。- このメソッドは、チャンクのトランザクションがコミットされる直前に呼び出されます。
- 注意点として、読み込み中に例外が発生し、トランザクションがロールバックされてアイテムが再読み込みされる場合、同じ原因で
onSkipInReadが繰り返し呼び出される可能性があります。リスナーの実装では、この再呼び出しを考慮する必要があります。
onSkipInProcess(T item, Throwable t):ItemProcessorでスキップ可能な例外が発生した場合に呼び出されます。- この場合、現在のチャンクのトランザクションはロールバックされます。Spring Batchはスキップされたアイテムを除外してチャンクを再処理し、新しいトランザクションで実行します。
onSkipInProcessは、この新しいチャンクのトランザクションがコミットされる直前に呼び出されます。
onSkipInWrite(T item, Throwable t):ItemWriterでスキップ可能な例外が発生した場合に呼び出されます。onSkipInProcessと同様に、現在のチャンクのトランザクションはロールバックされ、スキップされたアイテムを除外してチャンクが再処理されます。onSkipInWriteは、この新しいチャンクのトランザクションがコミットされる直前に呼び出されます。
3. SkipListener内でのトランザクション管理の注意点
SkipListener内でデータベース操作など、トランザクションを伴う処理を行う場合、以下の点に注意が必要です。
- 元のトランザクションへの依存を避ける:
SkipListenerのメソッドが呼び出される時点では、メインのバッチ処理のトランザクションはまだコミットされていません。- そのため、リスナー内で元のトランザクションに依存する処理を行うと、メインのトランザクションがロールバックされた場合に、リスナー内の処理もロールバックされてしまう可能性があります。
- 新しいトランザクションの明示的な管理:
SkipListener内で独立したトランザクション処理を実行する必要がある場合は、@Transactional(propagation = Propagation.REQUIRES_NEW)などのアノテーションを使用して、新しいトランザクションを明示的に開始・管理することを検討してください。- これにより、リスナー内の処理がメインのトランザクションから独立して動作し、堅牢性が向上します。
4. ベストプラクティスとユースケース
SkipListenerは、以下のようなシナリオで活用できます。
- スキップされたアイテムのログ記録:
- どのアイテムが、どのような理由でスキップされたかを詳細にログに記録することで、問題の特定や分析に役立ちます。
- エラーデータの隔離:
- スキップされたアイテムを別のエラーテーブルに移動させることで、メインの処理から問題のあるデータを隔離し、後で手動または別のバッチで処理できるようにします。
- 通知:
- スキップが発生した際に、管理者や関係者にメールやメッセージで通知することで、早期の問題検知と対応を可能にします。
Spring Batchのスキップとリスナーの具体的なハンズオンについては、以下の記事で詳細に解説していますので、是非ご覧ください。
3. 再起動可能性と冪等性の確保
Spring Batchで堅牢なバッチ処理を構築する上で、「再起動可能性」と「冪等性」は非常に重要な概念です。
これらを適切に理解し、設計に組み込むことで、予期せぬエラーや中断が発生しても、バッチ処理を安全かつ効率的に運用できます。
3-1. 再起動可能性 (Restartability) とは
再起動可能性とは、Spring Batchジョブが何らかの理由で途中で失敗したり中断したりした場合に、最初からやり直すのではなく、失敗した時点から処理を再開できる機能のことです。これは、大量のデータを処理するバッチ処理において、特にその価値を発揮します。
なぜ再起動可能性が重要なのか?
- 効率性:
- 大量のデータ処理中にジョブが失敗した場合、最初からやり直すと膨大な時間とリソースが無駄になります。
- 再起動できれば、既に処理が完了した部分はスキップし、未処理の部分から効率的に再開できます。
- データ整合性:
- 失敗した箇所から正確に再開することで、データの重複処理や処理漏れを防ぎ、データの一貫性を保ちやすくなります。
Spring Batchでの実現方法
Spring Batchは、ジョブの実行状態をJobRepositoryというコンポーネントに永続化することで、デフォルトで再起動可能性を提供しています。
JobRepositoryによる状態管理:JobRepositoryは、ジョブの開始時間、終了時間、ステータス、実行パラメータなどのメタデータをデータベースに保存します。
- 失敗時の記録:
- ジョブが失敗すると、
JobRepositoryにその情報が記録されます。
- ジョブが失敗すると、
- 再開時の参照:
- 同じジョブを再実行する際、Spring Batchは
JobRepositoryの情報を参照し、前回の失敗箇所を特定してそこから処理を再開します。
- 同じジョブを再実行する際、Spring Batchは
ItemReaderの進捗管理:- 特に
ItemReaderは、処理したレコード数などの進捗状況をExecutionContextに保存し、再起動時にその情報を使って読み込み位置を復元します。 - これにより、既に読み込んだデータを再度処理することなく、中断した箇所から読み込みを再開できます。
- 特に
注意点
JobRepositoryの永続化:JobRepositoryは、データベースなどの永続化ストアに接続されている必要があります。インメモリで管理されている場合、アプリケーションが再起動するとジョブの状態が失われ、再起動可能性が損なわれます。
ItemReaderの実装:- Spring Batchが提供する多くの
ItemReader(例:FlatFileItemReader、JdbcCursorItemReaderなど)は、デフォルトで状態を保存する機能をサポートしています。 - しかし、カスタムの
ItemReaderを実装する場合は、ItemStreamインターフェースを実装し、open()、update()、close()メソッドで進捗状況をExecutionContextに保存・復元するロジックを記述する必要があります。
- Spring Batchが提供する多くの
3-2. 冪等性 (Idempotency) とは
冪等性とは、「ある操作を何度実行しても、システムの状態が同じ結果になる」という特性のことです。つまり、同じ処理を1回実行しても、複数回実行しても、最終的な結果は常に同じであることを保証します。
なぜ冪等性が重要なのか?
- 再起動可能性との関連:
- ジョブが再起動された場合、一部の処理が複数回実行される可能性があります。このとき、処理が冪等であれば、データの重複登録や不整合といった問題を防ぐことができます。
- 信頼性:
- ネットワーク障害やシステムエラーなどで処理が中断し、自動的にリトライされるような場合でも、冪等性が保証されていれば、安心して再実行できます。
Spring Batchでの実現方法(開発者が考慮すべき点)
Spring Batch自体が自動的にすべての処理の冪等性を保証するわけではありません。
開発者がジョブのビジネスロジックを設計する際に、冪等性を意識し、適切な対策を講じる必要があります。
- 重複チェック:
- データベースのユニークキー制約: データをデータベースに書き込む際、ユニークキー制約を設定することで、同じデータが複数回挿入されるのを防ぎます。
- 書き込み前の存在確認:
ItemWriterでデータを書き込む前に、既に同じデータが存在しないかを確認し、存在しない場合のみ挿入するロジックを実装します。
- 更新処理 (UPSERT):
- データを挿入する代わりに、既存のデータを更新する(UPSERT: INSERT OR UPDATE)操作を利用することで、複数回実行されても最終的な状態は同じになります。
- 状態管理:
- 処理対象のデータ自体に「処理済み」などの状態フラグを持たせ、既に処理済みのデータはスキップするようにします。
- トランザクションの考慮:
- Spring Batchはチャンク処理においてトランザクションを管理しますが、トランザクションの範囲外で発生する副作用(例: 外部システムへのメッセージ送信、ファイル出力など)については、別途冪等性を考慮する必要があります。
- これらの操作は、複数回実行されても問題ないように設計するか、実行済みかどうかを判断できる仕組みを導入する必要があります。
具体例
CSVファイルから顧客データを読み込み、データベースの顧客テーブルに登録するバッチ処理を考えます。
- 再起動可能性の活用: ジョブが途中で失敗しても、
JobRepositoryとItemReaderの進捗管理により、中断した行から読み込みを再開できます。 - 冪等性の確保:
- 顧客テーブルの顧客IDカラムにユニークキー制約を設定します。
ItemWriterでは、受け取った顧客データに対して、まず顧客IDでデータベースを検索します。- もし顧客IDが既に存在すれば、その顧客データを更新(UPSERT)します。
- 存在しなければ、新規に挿入します。
このように設計することで、ジョブが再起動され、同じ顧客データがItemWriterに複数回渡されたとしても、データベースには重複データが登録されることなく、常に最新の顧客情報が保持されます。
3-3. 再起動可能性と冪等性の組み合わせ
再起動可能性と冪等性は、Spring Batchで堅牢なバッチ処理を構築するための両輪です。
- 再起動可能性は、ジョブの実行効率と運用性を高めます。
- 冪等性は、再起動やリトライによって発生しうるデータ不整合を防ぎ、処理の信頼性を保証します。
これら二つの概念を深く理解し、Spring Batchの機能と組み合わせて適切に設計・実装することで、どのような状況下でも安定して動作し、正確な結果を生成する高品質なバッチアプリケーションを実現できます。
バッチ処理が途中で停止した場合、最初からやり直すのではなく、停止した時点から再開できる「再起動可能性」は非常に重要です。
Spring Batchは、JobRepository がジョブの実行状態を永続化することで、これを自動的にサポートします。
また、同じ処理を複数回実行しても結果が変わらない「冪等性」も、バッチ処理の堅牢性を高める上で不可欠です。冪等性を確保するためには、以下のようなアプローチがあります。
- 排他制御: 処理対象のデータに対してロックをかける、またはステータスを更新することで、二重処理を防ぎます。
- 結果の検証: 処理後に結果が期待通りであることを検証し、不整合があれば修正します。
- ユニーク制約: データベースのユニーク制約を活用し、重複データの挿入を防ぎます。
まとめ
本記事では、Spring Batchで堅牢なバッチ処理を構築するための主要な設計パターンについて解説しました。
- エラーハンドリングとリトライ戦略: 一時的なエラーに対してはSpring Retryを活用した自動リトライが有効です。
@RetryableアノテーションやRetryTemplateを使って柔軟なリトライロジックを実装できます。 - スキップとリスナーの活用: 不正なデータや処理できないデータが存在する場合でも、
skip機能とSkipListenerを使って処理を継続し、エラーデータを隔離できます。 - 再起動可能性と冪等性の確保:
JobRepositoryによる実行状態の永続化で再起動可能性をサポートし、排他制御やユニーク制約などで冪等性を確保することが、安定したバッチ運用には不可欠です。
これらの堅牢性に関する設計パターンを理解し、適切に適用することで、予期せぬエラーにも強く、運用しやすいSpring Batchアプリケーションを開発できます。
Spring Batchにおけるリトライ設定の詳細は、以下の公式ドキュメントを参照してください。
免責事項
本記事の内容は、執筆時点での情報に基づいています。技術の進歩や環境の変化により、内容が古くなる可能性や、特定の環境では動作しない可能性があります。
本記事の内容を実践する際は、ご自身の責任において十分な検証を行ってください。
本記事によって生じたいかなる損害についても、筆者および公開元は一切の責任を負いません。