
はじめに:Java 25 LTSがもたらす並行処理の進化
2025年9月16日、Javaは新たなマイルストーンとなるJava 25をLTS(長期サポート)版として正式にリリースしました。
Java 21以来2年ぶりとなるこのLTSは、エンタープライズシステムに求められる安定性と、現代的な開発を加速する新機能を両立させています。
本記事では、Java 25における2つの重要な並行処理関連機能、「スコープ値(Scoped Values)」と「構造化並行性(Structured Concurrency)」の最新状況を解説します。
Java 25で正式機能となったスコープ値と、APIの改良が続きプレビューが継続される構造化並行性。
Java 21で導入された仮想スレッドとの関係性も踏まえ、これらの機能がJava開発にどのような影響を与えるのか、その現状と今後の展望を見ていきましょう。
目次
- 構造化並行性(Structured Concurrency):Java 25でもプレビュー継続
- 1-1. 構造化並行性とは何か?:エラー処理とキャンセル処理を大幅に簡素化
- 1-2. 仮想スレッドを使いこなすためのベストプラクティス
- 1-3. Spring Bootでの実践的なユースケース
- スコープ値(Scoped Values)の活用:Java 25で正式機能に
- 2-1. スレッドローカル変数との比較とスコープ値の優位性
- 2-2. 構造化並行性との連携
- Java 25のその他の主要な変更点
- まとめ:Java 25 LTSが示す、着実な進化
対象読者
- Javaの仮想スレッド(Virtual Threads)に関心のある開発者
CompletableFutureなど、従来の非同期処理に課題を感じている方- 最新のJava LTSの動向をキャッチアップしたいエンタープライズ開発者
- Spring Bootで、より効率的な並行処理を実装したい方
動作検証環境
この記事は、以下の環境で検証しています。
- OS : macOS Tahoe Version 26.1
- ハードウェア : MacBook Air 2024 M3 24GB
- VS Code: 最新版 (記事執筆時点)
- Java Extension Pack: 最新版 (記事執筆時点)
- Java: OpenJDK 25.0.1 LTS (Temurin)
1. 構造化並行性(Structured Concurrency):Java 25でもプレビュー継続
並行処理は、現代の高性能アプリケーション開発において不可欠な要素ですが、その複雑さゆえにバグの温床となりがちです。
構造化並行性は、この課題に対するJavaからの有力な解決策であり、Java 19からインキュベーションとプレビューが重ねられてきました。
Java 25では JEP 505として5回目のプレビューが実施され、APIのさらなる洗練が進められています。
1-1. 構造化並行性とは何か?:エラー処理とキャンセル処理を大幅に簡素化
構造化並行性とは、関連する複数の並行タスクを単一の作業単位として扱うためのAPIです。try-with-resources構文と組み合わせることで、スコープを抜ける際に全てのサブタスクが確実に終了するため、リソースリークや「孤児スレッド」の発生を防ぎます。
// 構造化並行性のコード例(Java 25 - 第5次プレビュー時点)
// JDK 25の新しいAPIでは、Joinerポリシーを指定してスコープを開きます
try (var scope = StructuredTaskScope.open(StructuredTaskScope.Joiner.allSuccessfulOrThrow())) {
// サブタスクをフォークします
Subtask<String> user = scope.fork(() -> findUser(true));
Subtask<Integer> order = scope.fork(() -> fetchOrder(true));
// サブタスクが完了するまで待機します
scope.join();
// 両方のタスクが成功した場合のみ、結果を処理します
System.out.println("User: " + user.get() + ", Order: " + order.get());
} catch (StructuredTaskScope.FailedException e) {
// エラーハンドリング:いずれかのタスクが失敗すると、もう一方は自動的にキャンセルされ、
// join()メソッドがFailedExceptionをスローします
System.err.println("Operation failed: " + e.getCause().getMessage());
}
// --- 以下はスタブメソッドです ---
private static String findUser(boolean success) throws InterruptedException {
System.out.println("Finding user...");
Thread.sleep(Duration.ofMillis(100));
if (!success) {
System.out.println("Failed to find user.");
throw new RuntimeException("Failed to find user");
}
System.out.println("Found user.");
return "John Doe";
}
private static Integer fetchOrder(boolean success) throws InterruptedException {
System.out.println("Fetching order...");
Thread.sleep(Duration.ofMillis(200));
if (!success) {
System.out.println("Failed to fetch order.");
throw new RuntimeException("Failed to fetch order");
}
System.out.println("Fetched order.");
return 12345;
}コードの振る舞い:
この例では、StructuredTaskScope.open() を使用して、タスクの成功・失敗を管理するポリシー(Joiner)を指定します。allSuccessfulOrThrow() ポリシーは、フォークされた全てのタスクが成功した場合にのみ処理を継続します。
scope.fork(...): 仮想スレッドでタスクを実行し、そのタスクを追跡するためのSubtaskを返します。scope.join(): 全てのタスクが完了するまで待機します。もしallSuccessfulOrThrowポリシーに反してタスクが1つでも失敗すると、この時点でStructuredTaskScope.FailedExceptionがスローされ、残りのタスクはキャンセルされます。catch (FailedException e): タスクの失敗をここで一元的に捕捉します。これにより、従来CompletableFutureなどで行っていた複雑なエラーハンドリングが大幅に簡素化されます。
実行結果の例:
成功ケースfindUser(true)とfetchOrder(true)を実行した場合、コンソールには以下のように出力されます。
Finding user...
Fetching order...
Found user.
Fetched order.
User: John Doe, Order: 12345失敗ケース
もしfetchOrder(false)のように失敗をシミュレートした場合、findUser()タスクは即座にキャンセルされ、catchブロックが実行されます。コンソールには以下のようなエラーメッセージが出力されます。
Finding user...
Fetching order...
Found user.
Failed to fetch order.
Operation failed: Failed to fetch order1-2. 仮想スレッドを使いこなすためのベストプラクティス
構造化並行性は、Java 21で正式機能となった 仮想スレッド(Virtual Threads) と組み合わせることで、その効果を最大限に引き出します。
仮想スレッドを効果的に利用するためのベストプラクティスは以下の通りです。
- スレッドプーリングは避ける:
- 仮想スレッドは生成コストが非常に低いため、タスクごとに
Executors.newVirtualThreadPerTaskExecutor()やThread.startVirtualThread()を使って生成するのが基本です。 - 従来のスレッドプールは不要です。
- 仮想スレッドは生成コストが非常に低いため、タスクごとに
synchronizedに注意(ピニング):synchronizedブロック内でI/O処理などのブロッキング操作を行うと、仮想スレッドがキャリアスレッド(OSスレッド)を解放できなくなる「ピニング」が発生します。- スケーラビリティを損なうため、
java.util.concurrent.locks.ReentrantLockの使用が推奨されます。
- I/Oバウンドなタスクに最適:
- 仮想スレッドは、ネットワーク通信やDBアクセスなど、待ち時間が多いI/Oバウンドな処理で最も効果を発揮します。
- CPUを集中的に使う処理(CPUバウンド)では大きなメリットはありません。
ThreadLocalからの移行:- 仮想スレッドは大量に生成される可能性があるため、
ThreadLocalを多用するとメモリ消費の問題や意図しない値の引き継ぎリスクがあります。 - 後述するスコープ値への移行が推奨されます。
- 仮想スレッドは大量に生成される可能性があるため、
図:仮想スレッドと構造化並行性の連携イメージ
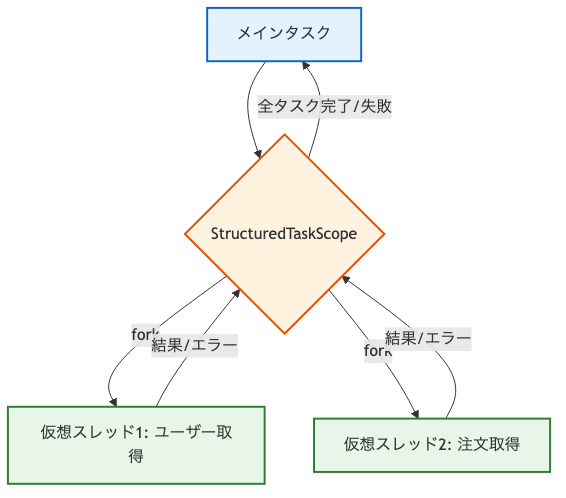
1-3. Spring Bootでの実践的なユースケース
Spring Bootアプリケーションでは、特に複数の外部マイクロサービスを呼び出して結果を統合するようなシナリオで、構造化並行性が非常に有効です。
このコードは、WebClientを使ったブロッキング呼び出しを並行して実行しています。
Spring Boot 3.2以降で仮想スレッドを有効にしていれば(spring.threads.virtual.enabled=true)、これらのブロッキング呼び出しは効率的に処理され、スレッドリソースを枯渇させることがありません。
構造化並行性により、非同期処理の複雑さを隠蔽し、同期的で読みやすいコードを維持できるのが大きな利点です。
// Spring Bootのサービス層での利用例
@Service
public class AggregationService {
private final WebClient webClient;
public AggregationService(WebClient.Builder webClientBuilder) {
this.webClient = webClientBuilder.build();
}
// 複数の外部APIを並行して呼び出し、結果を統合する
public AggregatedData fetchAggregatedData(long userId) throws InterruptedException {
// JDK 25のAPIに合わせてJoinerポリシーでスコープを開く
try (var scope = StructuredTaskScope.open(StructuredTaskScope.Joiner.allSuccessfulOrThrow())) {
// ユーザー情報取得APIを呼び出すサブタスク
Subtask<User> userSubtask = scope.fork(() ->
webClient.get().uri("/users/{id}", userId).retrieve().bodyToMono(User.class).block()
);
// ユーザーの最近の注文履歴を取得するサブタスク
Subtask<List<Order>> ordersSubtask = scope.fork(() ->
webClient.get().uri("/orders?userId={id}", userId).retrieve().bodyToFlux(Order.class).collectList().block()
);
// join()が完了するのを待つ。失敗時はここでFailedExceptionがスローされる
scope.join();
// 両方のAPI呼び出しが成功したら、結果をDTOに詰めて返す
return new AggregatedData(userSubtask.get(), ordersSubtask.get());
} catch (StructuredTaskScope.FailedException e) {
// 失敗時の例外処理
throw new RuntimeException("Failed to fetch aggregated data", e);
}
}
}コードの振る舞い:
このfetchAggregatedDataメソッドが呼び出されると、userFutureとordersFutureで定義された2つの外部API呼び出しが、それぞれ別の仮想スレッドで並行して実行されます。
- 成功した場合: 両方のAPI呼び出しが正常に完了すると、
join()メソッドが終了し、それぞれの結果がAggregatedDataオブジェクトにまとめられて返されます。 - 失敗した場合: もしどちらか一方のAPI呼び出しがタイムアウトやエラーで失敗すると、
ShutdownOnFailureポリシーに基づき、もう一方のタスクは即座にキャンセルされます。そしてthrowIfFailed()メソッドが例外をスローし、呼び出し元にエラーが伝播します。これにより、不要な待ち時間やリソースの浪費を防ぐことができます。
2. スコープ値(Scoped Values)の活用:Java 25で正式機能に
並行処理におけるもう一つの課題は、スレッド間での安全なデータ共有です。
Java 25では、この課題に対するシンプルな解決策としてスコープ値(Scoped Values) が JEP 506として正式機能になりました。
JDK 20からインキュベーションと複数回のプレビューを経て、安定機能として利用可能になりました。
2-1. スレッドローカル変数との比較とスコープ値の優位性
ThreadLocalは、各スレッドが独自の変数コピーを持つことを可能にしますが、特に数百万単位で生成されうる仮想スレッド環境では、以下の問題が顕在化します。
- メモリ消費:
- スレッドごとにデータがコピーされるため、メモリ消費が増大します。
- 意図しない継承:
- 親スレッドの
ThreadLocalの値が、スレッドプールなどで再利用された子スレッドに意図せず引き継がれてしまうリスクがあります。
- 親スレッドの
- 可変性:
ThreadLocalの値は可変であるため、コードの複雑さを増大させる要因となります。
スコープ値は、これらの問題を解決するために設計された、不変(immutable)で安価なデータ共有メカニズムです。
- 不変性と効率性:
- 値は不変であり、特定のコードブロック(スコープ)内でのみ有効です。子スレッドに共有される際もデータのコピーは発生せず、効率的です。
- 有界のライフタイム:
runやcallメソッドで定義されたスコープを抜けると、値は自動的に破棄されるため、メモリリークの心配がありません。
この例では、ScopedValue.where().run()を使用して、LOGGED_IN_USERが特定のスコープ内でのみ有効になるように設定しています。これにより、ThreadLocalで懸念された値の意図しない伝播を防ぎ、より安全で予測可能なデータ共有を実現します。
// スコープ値のコード例(Java 25 正式機能)
public class ScopedValueExample {
// ScopedValueはstatic finalとして宣言するのが一般的
public static final ScopedValue<String> LOGGED_IN_USER = ScopedValue.newInstance();
public static void main(String[] args) {
// "user-123"という値をLOGGED_IN_USERに束縛し、そのスコープ内で処理を実行
ScopedValue.where(LOGGED_IN_USER, "user-123").run(() -> new Service().process());
}
// Serviceクラス(スコープ値の例で使用)
static class Service {
void process() {
// スコープ内で設定された値を取得して利用
if (LOGGED_IN_USER.isBound()) {
System.out.println("Processing data for: " + LOGGED_IN_USER.get());
} else {
System.out.println("No user is logged in.");
}
}
}
}実行結果の例:
このコードを実行すると、mainメソッドで設定されたLOGGED_IN_USERの値がService#processメソッド内で取得され、コンソールに以下の通り出力されます。
Processing data for: user-1232-2. 構造化並行性との連携
スコープ値は、構造化並行性と組み合わせることで、親タスクのコンテキスト(認証情報、トランザクションIDなど)を、フォークされた複数の子タスク(仮想スレッド)に安全かつ自動的に継承させることができます。
これは、現代的なマイクロサービスアーキテクチャにおけるリクエストコンテキストの伝播などを、非常にシンプルに実装できることを意味します。
Java 25のその他の主要な変更点
Java 25では、この記事で特集した機能以外にも、開発者の生産性やパフォーマンスを向上させる多くの重要な改善が導入されました。
- モジュールインポート宣言(JEP 476, 正式機能):
import module構文が導入され、モジュール内の全てのパッケージを一度にインポートできるようになりました。これにより、特に大規模なライブラリを利用する際のimport文の記述が大幅に簡素化されます。 - コンパクトオブジェクトヘッダー(JEP 519, 正式機能):
オブジェクトのヘッダーサイズを削減することで、メモリ使用量を最適化し、アプリケーションのパフォーマンスを向上させます。特に、多数の小さなオブジェクトを生成するアプリケーションで効果が期待されます。 - Generational ZGC(JEP 439, JDK 21で導入済み):
低レイテンシが特徴のZGCに世代別GCを導入した機能です。JDK 21で利用可能になりましたが、Java 25時点でもデフォルトでは無効であり、-XX:+UseZGC -XX:+ZGenerationalオプションで有効化する必要があります。 - String Templates(文字列テンプレート)の状況:
JDK 21と22でプレビューされたこの機能は、設計の再検討のためJDK 23で一旦取り下げられ、Java 25には含まれませんでした。今後のリリースで、より洗練された形で再提案されることが期待されます。
まとめ:Java 25 LTSが示す、着実な進化
本記事では、2025年9月に正式リリースされたLTS版であるJava 25の主要な新機能、特に並行処理に関する改善点に焦点を当てて解説しました。
スコープ値が正式機能となり、ThreadLocalが抱えていた課題を解決する、安全で効率的なスレッド間データ共有の選択肢が提供されました。
一方で、構造化並行性は、APIの完成度を高めるためプレビューが継続されています。
これらの機能は、Java 21で導入された仮想スレッドを基盤として、その効果を最大限に発揮します。
Javaは着実に進化を続けています。
Java 25は、LTSとしての安定した基盤を提供すると同時に、現代的なアプリケーション開発の課題に対する新しい解決策を提示しています。
これらの新機能を理解し活用することで、Java開発の生産性とコードの品質をさらに向上させることができるでしょう。
Java 25の新機能を、ぜひ日々の開発に役立ててください。
免責事項
- 本記事の情報は、記事執筆時点(2025年9月)のJava 25 LTSおよび関連するJEP(Java Enhancement Proposal)に基づいています。
- 記事内で紹介しているプレビュー機能(構造化並行性など)は、将来のJavaバージョンで仕様が変更される可能性があります。
- サンプルコードは概念を説明するためのものであり、本番環境で使用する際は十分なテストとセキュリティ対策を行ってください。