
手作業からの解放!PDF自動化で業務を加速する
日々の業務で、PDFフォームへのデータ入力や、機密情報を含むPDFのセキュリティ設定に時間を取られていませんか? 申請書、報告書、契約書など、定型的なPDFフォームへの手作業での入力は、膨大な時間を消費するだけでなく、ヒューマンエラーの原因にもなりがちです。また、重要なドキュメントのセキュリティ対策は、情報漏洩リスクを回避するために不可欠です。
「もっと効率的に、もっと安全にPDFを扱いたい」
そうお考えのあなたに朗報です。Pythonの強力なPDFライブラリであるpypdfを使えば、これらの課題を劇的に解決できます。
本記事では、pypdfを活用してPDFフォームのデータを読み書きする方法から、パスワードによるPDFの保護といったセキュリティ設定まで、実践的な自動化テクニックを徹底解説します。
この記事を読み終える頃には、あなたは手作業によるPDF業務から解放され、より戦略的な業務に集中できるようになるでしょう。
対象読者
- PDFフォームへのデータ入力を自動化したい開発者
- PDFのセキュリティを強化したいエンジニア
- Pythonで業務効率化を目指すすべての方
pypdfの応用的な使い方を学びたい方
動作検証環境
この記事で紹介するPythonを使ったPDF動作は、以下の環境で検証しています。
- OS : macOS Tahoe Version 26.0
- ハードウェア : MacBook Air 2024 M3 24GB
- uv : 0.8.22 (ade2bdbd2 2025-09-23)
- python : 3.13.7
- pypdf : 6.1.1
目次
- PDFフォーム(AcroForm)の概要
pypdfでPDFフォームデータを読み取る- フォームフィールドの一覧取得
- 各フィールドの値の抽出
pypdfでPDFフォームデータを書き込む- テキストフィールドへの値の入力
- チェックボックスやラジオボタンの操作
- PDFのセキュリティ設定
- パスワードによるPDFの保護(閲覧・編集制限)
- 暗号化と復号化
- 実践例:申請書の自動入力と保護
- まとめ:
pypdfで実現する高度なPDF自動化- 今日からできる、はじめの一歩
- 次回の記事予告
- FAQ
- Q1:
pypdfで扱えるPDFフォームの種類は? - Q2: 日本語のフォームデータ入力で文字化けは発生しないか?
- Q3: パスワードを忘れてしまった場合、復旧できるか?
- Q4: フォームフィールドの名前がわからない場合、どうすればよいか?
- Q1:
- 参考資料
- 免責事項
1. PDFフォーム(AcroForm)の概要
PDFフォームとは、PDFドキュメント内にインタラクティブなフィールド(テキストボックス、チェックボックス、ラジオボタン、ドロップダウンリストなど)が埋め込まれたものです。これにより、ユーザーはPDFリーダー上で直接データを入力・選択できるようになります。
PDFフォームには主に「AcroForm」と「XFA (XML Forms Architecture)」の2種類がありますが、pypdfがサポートしているのはAcroFormです。AcroFormは、Adobe Acrobatで作成される一般的なPDFフォームであり、多くのビジネスシーンで利用されています。
pypdfは、このAcroFormのフィールド情報を読み取り、値を設定する機能を提供します。
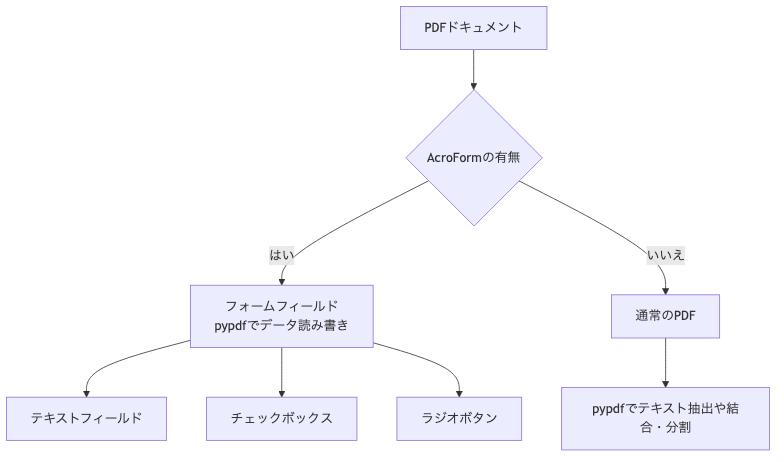
2. pypdfでPDFフォームデータを読み取る
まずは、既存のPDFフォームからフィールド情報や入力されているデータを読み取る方法を見ていきましょう。
フォームフィールドの一覧取得
PDFフォームに含まれるすべてのフィールド名を取得するには、PdfReaderオブジェクトのget_fields()メソッドを使用します。
from pypdf import PdfReader, PdfWriter
from pypdf.generic import Field
def get_pdf_form_fields(pdf_path: str) -> None:
"""
PDFフォームのフィールド名と現在の値を取得する関数
"""
reader = PdfReader(pdf_path)
fields: dict[str, Field] | None = reader.get_fields()
if fields:
print(f"PDFフォームのフィールド一覧 ({pdf_path}):")
for field_name, field_object in fields.items():
# .value はフィールドの値、/V はウィジェットの値
field_value = field_object.value
print(f" - フィールド名: {field_name}, 値: {field_value}")
else:
print(f"'{pdf_path}' にはフォームフィールドが見つかりませんでした。")
if __name__ == "__main__":
# --- ダミーフォームの作成 ---
# pypdfにはPDFフォームをゼロから「作成」する機能はありません。
# このスクリプトでフォームフィールドを正しく読み取るには、
# 実際にフォームフィールドを含むPDF(例: Adobe Acrobatで作成したもの)が必要です。
#
# 以下のコードは、スクリプトがエラーなく実行できるように、
# 単なる空のPDFを 'sample_form.pdf' として作成します。
# このファイルを、ご自身のフォーム付きPDFに置き換えてから実行してください。
writer = PdfWriter()
_ = writer.add_blank_page(width=72 * 8.5, height=72 * 11)
sample_form_path = "sample_form.pdf"
with open(sample_form_path, "wb") as fp:
_ = writer.write(fp)
print(f"ダミーのPDFを作成しました: {sample_form_path}")
print(
"注意: このPDFは空です。フォームフィールドを読み取るには、実際のフォームを含むPDFに置き換えてください。"
)
print("-" * 20)
# 作成した(または置き換えた)フォームのフィールドを読み取る
get_pdf_form_fields(sample_form_path)各フィールドの値の抽出
特定のフィールドの値を抽出したい場合は、get_fields()で取得した辞書からフィールド名を指定してアクセスします。
from typing import cast
from pypdf import PdfReader, PdfWriter
from pypdf.generic import Field
def extract_specific_field_value(pdf_path: str, field_name: str) -> str | None:
"""
PDFフォームから特定のフィールドの値を抽出する関数
"""
reader = PdfReader(pdf_path)
fields: dict[str, Field] | None = reader.get_fields()
if fields and field_name in fields:
value = fields[field_name].value
print(f"フィールド '{field_name}' の値: {value}")
return str(cast(object, value)) if value is not None else None
else:
print(f"フィールド '{field_name}' は見つかりませんでした。")
return None
if __name__ == "__main__":
# --- ダミーフォームの作成 ---
# pypdfにはPDFフォームをゼロから「作成」する機能はありません。
# このスクリプトでフォームフィールドを正しく読み取るには、
# 実際にフォームフィールドを含むPDF(例: Adobe Acrobatで作成したもの)が必要です。
#
# 以下のコードは、スクリプトがエラーなく実行できるように、
# 単なる空のPDFを 'sample_form.pdf' として作成します。
# このファイルを、ご自身のフォーム付きPDFに置き換えてから実行してください。
writer = PdfWriter()
_ = writer.add_blank_page(width=72 * 8.5, height=72 * 11)
sample_form_path = "sample_form.pdf"
with open(sample_form_path, "wb") as fp:
_ = writer.write(fp)
print(f"ダミーのPDFを作成しました: {sample_form_path}")
print(
"注意: このPDFは空です。フォームフィールドを読み取るには、実際のフォームを含むPDFに置き換えてください。"
)
print("-" * 20)
# 作成した(または置き換えた)フォームのフィールドを読み取る
_ = extract_specific_field_value(sample_form_path, "氏名")
_ = extract_specific_field_value(sample_form_path, "メールアドレス")3. pypdfでPDFフォームデータを書き込む
次に、PythonコードからPDFフォームにデータを入力し、必要に応じてフォームを編集不可にする方法を学びます。
テキストフィールドへの値の入力
PdfWriterオブジェクトのupdate_page_form_field_values()メソッドを使って、フォームフィールドに値を設定します。
from pypdf import PdfReader, PdfWriter
from pypdf.generic import Field
def get_pdf_form_fields(pdf_path: str) -> None:
"""
PDFフォームのフィールド名と現在の値を取得する関数
"""
reader = PdfReader(pdf_path)
fields: dict[str, Field] | None = reader.get_fields()
if fields:
print(f"PDFフォームのフィールド一覧 ({pdf_path}):")
for field_name, field_object in fields.items():
field_value = field_object.value
print(f" - フィールド名: {field_name}, 値: {field_value}")
else:
print(f"'{pdf_path}' にはフォームフィールドが見つかりませんでした。")
def fill_pdf_form(
input_pdf_path: str,
output_pdf_path: str,
data_to_fill: dict[str, str | list[str] | tuple[str, str, float]],
) -> None:
"""
PDFフォームにデータを入力し、新しいPDFとして保存する関数
"""
reader = PdfReader(input_pdf_path)
# フォームフィールドが存在するかどうかを確認
if not reader.get_fields():
print(
f"警告: '{input_pdf_path}' には入力可能なフォームフィールドが見つかりませんでした。"
)
# フィールドがない場合、単にファイルをコピーするか、あるいは何もしない
# ここでは、単にコピーを作成します
writer = PdfWriter()
writer.clone_document_from_reader(reader)
with open(output_pdf_path, "wb") as output_file:
_ = writer.write(output_file)
print(f"入力フォームがないため、ファイルをコピーしました: '{output_pdf_path}'")
return
writer = PdfWriter()
writer.clone_document_from_reader(reader) # 既存のドキュメントをクローン
# フォームフィールドにデータを入力
for page_num in range(len(writer.pages)):
writer.update_page_form_field_values(
writer.pages[page_num],
data_to_fill,
)
with open(output_pdf_path, "wb") as output_file:
_ = writer.write(output_file)
print(f"フォームにデータを入力し、'{output_pdf_path}' として保存しました。")
if __name__ == "__main__":
# --- ダミーフォームの作成 ---
# pypdfにはPDFフォームをゼロから「作成」する機能はありません。
# このスクリプトでフォームを埋めるには、
# 実際にフォームフィールドを含むPDF(例: Adobe Acrobatで作成したもの)が必要です。
#
# 以下のコードは、スクリプトがエラーなく実行できるように、
# 単なる空のPDFを 'sample_form.pdf' として作成します。
# このファイルを、ご自身のフォーム付きPDFに置き換えてから実行してください。
writer = PdfWriter()
_ = writer.add_blank_page(width=72 * 8.5, height=72 * 11)
input_pdf_path = "sample_form.pdf"
with open(input_pdf_path, "wb") as fp:
_ = writer.write(fp)
print(f"ダミーのPDFを作成しました: {input_pdf_path}")
print(
"注意: このPDFは空です。フォームフィールドを埋めるには、実際のフォームを含むPDFに置き換えてください。"
)
print("-" * 20)
# --- フォームへの入力 ---
form_data: dict[str, str | list[str] | tuple[str, str, float]] = {
"氏名": "山田 太郎",
"メールアドレス": "taro.yamada@example.com",
"電話番号": "090-1234-5678",
}
output_pdf_path = "filled_form.pdf"
# 注: 上記で作成された空のPDFに対して実行するため、実際には何も入力されません。
fill_pdf_form(input_pdf_path, output_pdf_path, form_data)
# --- (オプション) 入力後のPDFのフィールド値を確認 ---
print("-" * 20)
print("入力後のPDFのフィールド値を確認します。")
# 注: 空のPDFなので、フィールドは検出されません。
get_pdf_form_fields(output_pdf_path)チェックボックスやラジオボタンの操作
チェックボックスやラジオボタンも、テキストフィールドと同様にupdate_page_form_field_values()で操作できます。値はフィールドのプロパティによって異なりますが、一般的には'Yes'や'Off'、または選択肢の文字列を指定します。
from pypdf import PdfReader, PdfWriter
from pypdf.generic import Field
def fill_checkbox_radio(
input_pdf_path: str,
output_pdf_path: str,
checkbox_data: dict[str, str | list[str] | tuple[str, str, float]],
) -> None:
"""
PDFフォームのチェックボックスやラジオボタンにデータを入力する関数
"""
reader = PdfReader(input_pdf_path)
# フォームフィールドが存在するかどうかを確認
if not reader.get_fields():
print(
f"警告: '{input_pdf_path}' には入力可能なフォームフィールドが見つかりませんでした。"
)
writer = PdfWriter()
writer.clone_document_from_reader(reader)
with open(output_pdf_path, "wb") as output_file:
_ = writer.write(output_file)
print(f"入力フォームがないため、ファイルをコピーしました: '{output_pdf_path}'")
return
writer = PdfWriter()
writer.clone_document_from_reader(reader)
# フォームフィールドにデータを入力
for page_num in range(len(writer.pages)):
writer.update_page_form_field_values(
writer.pages[page_num],
checkbox_data,
)
with open(output_pdf_path, "wb") as output_file:
_ = writer.write(output_file)
print(
f"チェックボックス/ラジオボタンにデータを入力し、'{output_pdf_path}' として保存しました。"
)
if __name__ == "__main__":
# --- ダミーフォームの作成 ---
writer = PdfWriter()
_ = writer.add_blank_page(width=72 * 8.5, height=72 * 11)
input_pdf_path = "sample_form_with_checkbox.pdf"
with open(input_pdf_path, "wb") as fp:
_ = writer.write(fp)
print(f"ダミーのPDFを作成しました: {input_pdf_path}")
print(
"注意: このPDFは空です。フォームフィールドを埋めるには、実際のフォームを含むPDFに置き換えてください。"
)
print("-" * 20)
# --- フォームへの入力 ---
checkbox_radio_data: dict[str, str | list[str] | tuple[str, str, float]] = {
"同意チェックボックス": "/Yes",
"性別": "/男性",
}
output_pdf_path = "filled_checkbox_form.pdf"
fill_checkbox_radio(input_pdf_path, output_pdf_path, checkbox_radio_data)
# --- (オプション) 入力後のPDFのフィールド値を確認 ---
print("-" * 20)
print("入力後のPDFのフィールド値を確認します。")
try:
reader_check = PdfReader(output_pdf_path)
fields: dict[str, Field] | None = reader_check.get_fields()
if fields:
print(f"PDFフォームのフィールド一覧 ({output_pdf_path}):")
for field_name, field_object in fields.items():
field_value = field_object.value
print(f" - フィールド名: {field_name}, 値: {field_value}")
else:
print(f"'{output_pdf_path}' にはフォームフィールドが見つかりませんでした。")
except Exception as e:
print(f"フィールドの読み取り中にエラーが発生しました: {e}")[!NOTE]
チェックボックスやラジオボタンの値は、PDFフォームの作成方法によって異なります。/Yesや/Offが一般的ですが、フィールドのプロパティを確認するか、試行錯誤して正しい値を見つける必要があります。
4. PDFのセキュリティ設定
pypdfは、PDFにパスワードを設定して保護する機能も提供します。これにより、不正な閲覧や編集を防ぐことができます。
パスワードによるPDFの保護(閲覧・編集制限)
encrypt()メソッドを使用すると、PDFにパスワードを設定できます。ユーザーパスワードとオーナーパスワードの2種類があり、それぞれ異なる権限を付与できます。
- ユーザーパスワード: PDFの閲覧を許可するためのパスワード。
- オーナーパスワード: PDFの閲覧に加え、印刷、コピー、編集などの操作を許可するためのパスワード。
from pypdf import PdfReader, PdfWriter
from pypdf.errors import DependencyError
def protect_pdf_with_password(
input_pdf_path: str,
output_pdf_path: str,
user_password: str,
owner_password: str | None = None,
) -> None:
"""
PDFにパスワードを設定して保護する関数
"""
reader = PdfReader(input_pdf_path)
writer = PdfWriter()
for page in reader.pages:
_ = writer.add_page(page)
# パスワードを設定
try:
writer.encrypt(user_password, owner_password)
except DependencyError:
print("エラー: この機能にはPyCryptodomeが必要です。")
print("pip install pypdf[crypto] を実行してください。")
return
with open(output_pdf_path, "wb") as output_file:
_ = writer.write(output_file)
print(f"PDFをパスワードで保護し、'{output_pdf_path}' として保存しました。")
if __name__ == "__main__":
# --- ダミーの入力PDFを作成 ---
input_pdf_path = "sample_document.pdf"
writer_dummy = PdfWriter()
_ = writer_dummy.add_blank_page(width=72 * 8.5, height=72 * 11)
with open(input_pdf_path, "wb") as fp:
_ = writer_dummy.write(fp)
print(f"ダミーの入力PDFを作成しました: {input_pdf_path}")
print("-" * 20)
# --- PDFの保護 ---
output_pdf_path = "protected_document.pdf"
user_pw = "user_password_123"
owner_pw = "owner_password_456" # オプション
protect_pdf_with_password(input_pdf_path, output_pdf_path, user_pw, owner_pw)
# --- (オプション) 保護されたPDFの確認 ---
print("-" * 20)
print("保護されたPDFが読み取り可能か確認します。")
try:
# パスワードなしで読み取りを試みる(失敗するはず)
reader_check1 = PdfReader(output_pdf_path)
if reader_check1.is_encrypted:
print("OK: パスワードなしでは読み取れません(暗号化されています)。")
else:
print(
"警告: パスワードなしで読み取れました(暗号化に失敗した可能性があります)。"
)
# 正しいパスワードで読み取りを試みる(成功するはず)
reader_check2 = PdfReader(output_pdf_path)
if reader_check2.decrypt(user_pw):
print(f"OK: パスワード '{user_pw}' で正常に読み取れました。")
print(f"ページ数: {len(reader_check2.pages)}")
else:
print(f"警告: パスワード '{user_pw}' で読み取れませんでした。")
except Exception as e:
print(f"保護されたPDFの確認中にエラーが発生しました: {e}")[!NOTE]encrypt()メソッドの第2引数owner_passwordを省略した場合、ユーザーパスワードのみが設定され、PDFの閲覧は可能ですが、編集などの操作は制限されます。オーナーパスワードを設定すると、そのパスワードを知っているユーザーはすべての操作が可能になります。
暗号化と復号化
パスワードで保護されたPDFを読み込む際は、PdfReaderの初期化時にパスワードを指定する必要があります。
from pypdf import PdfReader, PdfWriter
from pypdf.errors import DependencyError
def read_protected_pdf(pdf_path: str, password: str) -> None:
"""
パスワードで保護されたPDFを読み込む関数
"""
try:
reader = PdfReader(pdf_path)
if reader.is_encrypted:
if reader.decrypt(password):
print(f"'{pdf_path}' をパスワードで復号化しました。")
# ここから通常のPDF操作が可能
print(f"ページ数: {len(reader.pages)}")
# 最初のページのテキストを抽出(テキストがない場合も考慮)
first_page_text = reader.pages[0].extract_text()
if first_page_text:
print(f"最初のページのテキスト:\n{first_page_text[:200]}...")
else:
print("最初のページにテキストが見つかりませんでした。")
else:
print(
f"'{pdf_path}' の復号に失敗しました。パスワードが違う可能性があります。"
)
else:
print(f"'{pdf_path}' は暗号化されていません。")
except DependencyError:
print("エラー: この機能にはPyCryptodomeが必要です。")
print("pip install pypdf[crypto] を実行してください。")
except Exception as e:
print(f"PDFの読み込みまたは復号化に失敗しました: {e}")
if __name__ == "__main__":
# --- ダミーの保護済みPDFを作成 ---
protected_pdf_path = "protected_document.pdf"
user_pw = "user_password_123"
writer_dummy = PdfWriter()
_ = writer_dummy.add_blank_page(width=72 * 8.5, height=72 * 11)
# extract_textで何か表示されるように、注釈としてテキストを追加
_ = writer_dummy.add_annotation(
page_number=0,
annotation={
"/Type": "/Annot",
"/Subtype": "/FreeText",
"/Rect": [0, 0, 0, 0], # 表示されないように
"/Contents": "This is a sample text on the first page.",
},
)
try:
writer_dummy.encrypt(user_pw)
with open(protected_pdf_path, "wb") as fp:
_ = writer_dummy.write(fp)
print(f"ダミーの保護済みPDFを作成しました: {protected_pdf_path}")
except DependencyError:
print("エラー: 保護されたPDFの作成にはPyCryptodomeが必要です。")
print("pip install pypdf[crypto] を実行してください。")
# cryptoがない場合、スクリプトの残りの部分を実行しても意味がないので終了
exit()
print("-" * 20)
# --- 保護されたPDFの読み込み ---
read_protected_pdf(protected_pdf_path, user_pw)
# --- (おまけ) 間違ったパスワードで試す ---
print("-" * 20)
print("間違ったパスワードで読み込みを試みます。")
read_protected_pdf(protected_pdf_path, "wrong_password")5. 実践例:申請書の自動入力と保護
これまでの知識を組み合わせて、具体的な業務自動化のシナリオを考えてみましょう。ここでは、「従業員の交通費申請書を自動入力し、上長承認後にパスワードを設定して保護する」というケースを想定します。
import datetime
import os
from pypdf import PdfReader, PdfWriter
from pypdf.errors import DependencyError
from pypdf.generic import Field
def automate_expense_report(
template_path: str,
output_path: str,
employee_data: dict[str, str],
expenses: list[dict[str, str | int]],
) -> None:
"""
交通費申請書を自動入力し、保護する関数
"""
try:
reader = PdfReader(template_path)
except FileNotFoundError:
print(f"エラー: テンプレートファイル '{template_path}' が見つかりません。")
return
# フォームフィールドが存在するかどうかを確認
if not reader.get_fields():
print(
f"警告: '{template_path}' には入力可能なフォームフィールドが見つかりませんでした。"
)
return
writer = PdfWriter()
writer.clone_document_from_reader(reader)
# 申請日を自動入力
today = datetime.date.today().strftime("%Y/%m/%d")
employee_data["申請日"] = today
# 従業員情報と交通費明細を結合
all_form_data: dict[str, str | list[str] | tuple[str, str, float]] = {
**employee_data
}
for i, expense in enumerate(expenses):
all_form_data[f"日付{i + 1}"] = str(expense["date"])
all_form_data[f"内容{i + 1}"] = str(expense["description"])
all_form_data[f"金額{i + 1}"] = str(expense["amount"])
# フォームフィールドにデータを一括で入力
for page_num in range(len(writer.pages)):
writer.update_page_form_field_values(
writer.pages[page_num],
all_form_data,
)
# 上長パスワードで保護
try:
writer.encrypt(user_password="", owner_password="manager_password_789")
except DependencyError:
print("エラー: PDFの暗号化にはPyCryptodomeが必要です。")
print("pip install pypdf[crypto] を実行してください。")
except Exception as e:
print(f"暗号化中に予期せぬエラーが発生しました: {e}")
with open(output_path, "wb") as output_file:
_ = writer.write(output_file)
print(f"交通費申請書を自動入力・保護し、'{output_path}' として保存しました。")
if __name__ == "__main__":
template_pdf = "expense_report_template.pdf"
print("--- 交通費申請書 自動作成スクリプト ---")
print(f"テンプレートとして '{template_pdf}' を使用します。")
if not os.path.exists(template_pdf):
writer_dummy = PdfWriter()
_ = writer_dummy.add_blank_page(width=72 * 8.5, height=72 * 11)
with open(template_pdf, "wb") as fp:
_ = writer_dummy.write(fp)
print(f"\nダミーのテンプレートPDFを作成しました: {template_pdf}")
print("注意: このテンプレートは空です。")
print(
"スクリプトを正しく動作させるには、以下のフォームフィールドを持つPDFに置き換えてください:"
)
print(" - 氏名, 部署, 社員番号, 申請日")
print(" - 日付1, 内容1, 金額1")
print(" - 日付2, 内容2, 金額2")
print(" - ... (必要なだけ)")
print("-" * 20)
employee_info = {"氏名": "鈴木 花子", "部署": "開発部", "社員番号": "E001"}
expense_details = [
{"date": "2025/09/20", "description": "電車賃(自宅-会社)", "amount": 500},
{"date": "2025/09/21", "description": "バス代(会社-顧客先)", "amount": 300},
{"date": "2025/09/22", "description": "電車賃(自宅-会社)", "amount": 500},
]
output_pdf = "completed_expense_report.pdf"
automate_expense_report(template_pdf, output_pdf, employee_info, expense_details)
print("-" * 20)
print(f"生成されたPDF '{output_pdf}' の内容を確認します。")
if os.path.exists(output_pdf):
try:
reader_check = PdfReader(output_pdf)
if reader_check.is_encrypted:
print("OK: PDFはパスワードで保護されています。")
if reader_check.decrypt("manager_password_789"):
print("OK: オーナーパスワードで復号できました。")
else:
print("警告: オーナーパスワードで復号できませんでした。")
else:
print("警告: PDFがパスワードで保護されていません。")
fields: dict[str, Field] | None = reader_check.get_fields()
if fields:
print("\n入力されたフォームフィールド:")
for field_name, field_object in fields.items():
if field_object.value:
print(f" - {field_name}: {field_object.value}")
else:
print("フォームフィールドが見つかりませんでした。")
except Exception as e:
print(f"生成されたPDFの確認中にエラーが発生しました: {e}")
else:
print(f"エラー: 出力ファイル '{output_pdf}' が見つかりません。")[!TIP]
PDFフォームのフィールド名は、Adobe AcrobatなどのPDF編集ソフトで確認できます。また、pypdfで一度フィールド名の一覧を取得し、それを参考にスクリプトを作成すると効率的です。
まとめ:pypdfで実現する高度なPDF自動化
本記事では、pypdfを使ったPDFフォームのデータ操作とセキュリティ設定について詳しく解説しました。
- PDFフォームデータの読み書き:
get_fields()でフィールド情報を取得し、update_page_form_field_values()でデータを入力。 - PDFのセキュリティ設定:
encrypt()でパスワードを設定し、閲覧や編集を制限。
これらの機能を活用することで、手作業で行っていた定型業務をPythonで自動化し、業務効率を大幅に向上させることができます。特に、申請書や報告書の自動生成、機密文書のセキュリティ強化といった場面で、pypdfは強力なツールとなるでしょう。
今日からできる、はじめの一歩
まずは、身近にあるPDFフォーム(例えば、Webからダウンロードした申請書テンプレートなど)を使って、フィールド名を取得し、簡単なデータを入力するスクリプトを書いてみましょう。そして、そのPDFをパスワードで保護してみてください。小さな成功体験が、次の自動化への大きな一歩となります。
次回の記事予告
次回の記事では、pypdfとは異なるアプローチでPDFを扱う「ReportLab」に焦点を当てます。ReportLabは、PythonコードでPDFをゼロから生成するための強力なライブラリです。複雑なレイアウトやグラフ描画を含むプロフェッショナルなPDFを作成する方法を深掘りします。お楽しみに!
[関連記事「pypdf実践:PDFの結合・分割、ページ操作でドキュメントを効率化する」]
[関連記事「ReportLab入門:PythonでPDFをゼロから生成する基礎」]
FAQ
Q1: pypdfで扱えるPDFフォームの種類は?
A1: pypdfは主にAcroForm形式のPDFフォームをサポートしています。XFA (XML Forms Architecture) 形式のフォームは直接サポートしていません。XFAフォームを扱う場合は、別のライブラリやツールを検討する必要があります。
Q2: 日本語のフォームデータ入力で文字化けは発生しないか?
A2: pypdf自体はUTF-8エンコーディングをサポートしているため、基本的には日本語の文字化けは発生しにくいです。しかし、PDFフォームが埋め込みフォントを適切に持っていない場合や、特定のPDFリーダーとの相性によっては表示が崩れる可能性もゼロではありません。フラット化する前に、生成されたPDFを複数のPDFリーダーで確認することをお勧めします。
Q3: パスワードを忘れてしまった場合、復旧できるか?
A3: pypdfで設定したパスワードを忘れてしまった場合、復旧することは非常に困難です。特にオーナーパスワードを忘れると、PDFの編集や印刷ができなくなる可能性があります。パスワードは厳重に管理し、安全な場所に保管するようにしてください。
Q4: フォームフィールドの名前がわからない場合、どうすればよいか?
A4: フォームフィールドの名前が不明な場合は、本記事で紹介したget_pdf_form_fields()関数を使って、まずフィールド名の一覧を取得してください。Adobe AcrobatなどのPDF編集ソフトウェアでもフィールド名を確認できます。
参考資料
pypdf公式ドキュメント: https://pypdf.readthedocs.io/- PyPI – pypdf: https://pypi.org/project/pypdf/
免責事項
本記事の内容は、執筆時点での情報に基づいています。pypdfのバージョンアップや関連技術の変更により、内容が古くなる可能性があります。コードの利用は自己責任でお願いします。