
はじめに:単一ライブラリの限界を超え、PDF自動化の未来へ
PDF処理の自動化を進める中で、特定のタスクでは優れた性能を発揮するライブラリも、別のタスクでは力不足を感じることはないでしょうか?
例えば、大量のPDFから高速にテキストや画像を抽出したい場合はPyMuPDFが強力ですが、複雑なレイアウトを持つ帳票をゼロから生成するならReportLabに軍配が上がります。
また、既存のPDFの結合や分割といった基本的な操作はpypdfで手軽に実現できますが、その後の詳細なコンテンツ解析にはPyMuPDFの高速性が求められるかもしれません。
このように、それぞれのPython PDFライブラリが持つ「得意分野」を最大限に活かし、それらを連携させることで、単一ライブラリでは到達し得なかった高度で柔軟なPDF処理ワークフローを構築することが可能になります。
本記事は、この「Python PDFライブラリ徹底活用ガイド」シリーズの集大成として、PyMuPDFの応用的な機能である「高度なレンダリング」と「注釈操作」を深掘りします。
さらに、本シリーズのコンセプトである「複数ライブラリ連携」を具体的に解説し、PyMuPDFと他のPDFライブラリ(pypdf, ReportLab)を組み合わせることで、より複雑で効率的なPDF自動化システムを構築するための実践的なテクニックを提供します。
この記事を読み終える頃には、あなたは単一ライブラリの限界を超え、自身のプロジェクトに最適な、より高度なPDF自動化システムを設計・実装できるようになるでしょう。PDF処理の「未来」を切り拓き、自動化の可能性を最大限に引き出すための知識とテクニックを、ぜひここで習得してください。
対象読者
- PyMuPDFの基本的な使い方を習得し、さらに高度なPDF処理に挑戦したい方。
- 複数のPython PDFライブラリを組み合わせて、より複雑な自動化ワークフローを構築したい方。
- PDFのレンダリング、注釈操作、ライブラリ連携に興味がある中級者以上のPython開発者。
動作検証環境
この記事で紹介するPythonを使ったPDF動作は、以下の環境で検証しています。
- OS : macOS Tahoe Version 26.0
- ハードウェア : MacBook Air 2024 M3 24GB
- uv : 0.8.22 (ade2bdbd2 2025-09-23)
- python : 3.13.7
- pypdf : 6.1.1
- PyMuPDF : 1.26.4
- pymupdf-stubs : 1.26.1.post1
- ReportLab : 4.4.4
- charset-normalizer : 3.4.3
- pillow : 11.3.0
- pandas : 2.3.3
- numpy : 2.3.3
- python-dateutil : 2.9.0.post0
- six : 1.17.0
- pytz : 2025.2
- types-pytz (型ヒント) : 2025.2.0.20250809
- tzdata : 2025.2
- pandas-stubs : 2.3.2.250926
目次
- 高度なPDFレンダリング
- 特定の領域のレンダリング
- 透明度やブレンドモードの制御
- PDF注釈(アノテーション)の操作
- テキスト注釈、ハイライト、図形注釈の追加
- テキスト注釈(コメント)の追加
- ハイライト注釈の追加
- 図形注釈(矩形)の追加
- 実践例:注釈の作成と読み取り
- 実践例:PDFレビュープロセスの自動化
- テキスト注釈、ハイライト、図形注釈の追加
- PyMuPDFと他のライブラリとの連携
- PyMuPDFで抽出したテキスト/画像をReportLabで再利用
pypdfで結合したPDFをPyMuPDFで高速処理- 複数ライブラリ連携のワークフロー例
- まとめ:Python PDF処理の未来と自動化の可能性
- 今日からできる、はじめの一歩
- FAQ
- 参考資料
- 免責事項
1. 高度なPDFレンダリング
PyMuPDFは、PDFドキュメントを画像としてレンダリングする強力な機能を持っています。単にページ全体を画像化するだけでなく、特定の領域のみをレンダリングしたり、透明度やブレンドモードを制御したりすることで、より柔軟な画像処理が可能になります。
特定の領域のレンダリング
PDFページの一部だけを画像として抽出したい場合、Page.get_pixmap() メソッドの clip パラメータを使用します。これは、ページの座標系における矩形領域を指定するものです。
import pymupdf
# PDFファイルを開く
doc = pymupdf.open("image_report.pdf")
page = doc[0] # 最初のページを取得
# レンダリングしたい領域を定義 (x0, y0, x1, y1)
# 例: ページの左上1/4の領域
clip_rect = pymupdf.Rect(0, 0, page.rect.width / 2, page.rect.height / 2)
# 指定した領域をレンダリング
pix = page.get_pixmap(clip=clip_rect)
# 画像として保存
pix.save("clipped_area.png")
doc.close()
print("指定領域のレンダリングが完了しました: clipped_area.png")clip パラメータを適切に使うことで、例えばPDF内の特定のグラフや表、ロゴだけを画像として切り出すといった処理が容易になります。
透明度やブレンドモードの制御
Page.get_pixmap() メソッドは、レンダリング時の透明度(アルファチャンネル)や色空間の制御も可能です。これにより、より高品質な画像出力や、特定の用途に合わせた画像生成が行えます。
例えば、背景が透明なPNG画像を生成したい場合、alpha=True を指定します。
import pymupdf
doc = pymupdf.open("image_report.pdf")
page = doc[0]
# アルファチャンネル付きでレンダリング
# 背景が透明なPNG画像を生成したい場合に有用
pix_alpha = page.get_pixmap(alpha=True)
pix_alpha.save("page_with_alpha.png")
doc.close()
print("アルファチャンネル付きのレンダリングが完了しました: page_with_alpha.png")[!NOTE]get_pixmap()のmatrixパラメータを使用すると、レンダリング時の拡大・縮小、回転、せん断などの変換を細かく制御できます。これにより、高解像度での出力や、特定の視覚効果を適用したレンダリングが可能です。
2. PDF注釈(アノテーション)の操作
PDFの注釈(アノテーション)は、テキストのハイライト、コメント、図形、スタンプなど、ドキュメントに情報を追加するための機能です。PyMuPDFは、これらの注釈をプログラムから読み取り、追加、編集する強力な機能を提供します。
テキスト注釈、ハイライト、図形注釈の追加
PyMuPDFを使えば、プログラムから新しい注釈をPDFに追加することも簡単です。ここでは、代表的な注釈の追加方法を紹介します。
テキスト注釈(コメント)の追加
Page.add_text_annot() を使用して、指定した位置にテキストコメントを追加できます。
import pymupdf
import os
# 新しいドキュメントとページを作成
doc = pymupdf.open()
page = doc.new_page(width=595, height=842)
# テキスト注釈を追加する位置 (矩形)
text_annot_pos = pymupdf.Point(50, 120)
page.add_text_annot(
text_annot_pos, "これはText注釈の\nポップアップコメントです。", icon="Comment"
)
file_path = "annotated_with_text.pdf"
doc.save(file_path, garbage=4, deflate=True)
doc.close()
print(f"テキスト注釈が追加されました: {file_path}")
# クリーンアップ
# if os.path.exists(file_path):
# os.remove(file_path)ハイライト注釈の追加
特定のテキスト範囲をハイライト表示するには、Page.add_highlight_annot() を使用します。
import pymupdf
import os
# 新しいドキュメントとページを作成
doc = pymupdf.open()
page = doc.new_page(width=595, height=842)
text_to_highlight = "このテキストをハイライトします"
red = (1, 0, 0)
# まず、注釈をつけたいテキストをページに書き込む
page.insert_text(pymupdf.Point(50, 200), text_to_highlight, fontsize=11)
# 書き込んだテキストの位置を正確に探し出す
highlight_quads = page.search_for(text_to_highlight, quads=True)
# 探し出した位置情報を使って注釈を追加
if highlight_quads:
annot = page.add_highlight_annot(highlight_quads[0])
annot.set_colors(stroke=red) # 色を設定
annot.update()
file_path = "annotated_with_highlight.pdf"
doc.save(file_path, garbage=4, deflate=True)
doc.close()
print(f"ハイライト注釈が追加されました: {file_path}")
# クリーンアップ
# if os.path.exists(file_path):
# os.remove(file_path)図形注釈(矩形)の追加
Page.add_rect_annot() を使用して、指定した領域に矩形の図形注釈を追加できます。
import pymupdf
import os
# 新しいドキュメントとページを作成
doc = pymupdf.open()
page = doc.new_page(width=595, height=842)
# 矩形注釈を追加する領域
rect_annot_rect = pymupdf.Rect(300, 50, 400, 150)
page.add_rect_annot(rect_annot_rect)
file_path = "annotated_with_rect.pdf"
doc.save(file_path, garbage=4, deflate=True)
doc.close()
print(f"矩形注釈が追加されました: {file_path}")
# クリーンアップ
# if os.path.exists(file_path):
# os.remove(file_path)実践例:注釈の作成と読み取り
それでは、今まで説明してきた操作を総合的に活用して、注釈の作成と読み取りを行うサンプルを紹介します。
PDFドキュメントに既存の注釈がある場合、Page.annots() メソッドを使ってそれらを取得し、詳細情報を読み取ることができます。
テキスト注釈、ハイライト、図形注釈の追加と読み取りを行うサンプルコード:
import pymupdf
import os
# --- 1. より高度な方法で注釈付きサンプルPDFを作成 ---
file_path = "annotated_sample.pdf"
print(f"注釈付きサンプルPDF '{file_path}' を作成します...")
# テキストや色の定義
text_to_highlight = "このテキストをハイライトします"
text_to_underline = "このテキストに下線を引きます"
red = (1, 0, 0)
blue = (0, 0, 1)
gold = (1, 1, 0)
# 新しいドキュメントとページを作成
doc = pymupdf.open()
page = doc.new_page(width=595, height=842)
# --- 注釈を追加 ---
# (A) FreeText (自由なテキスト) 注釈
freetext_rect = pymupdf.Rect(50, 50, 250, 100)
page.add_freetext_annot(
freetext_rect,
"これはFreeText注釈です。\n回転もできます。",
fontsize=12,
rotate=10,
text_color=blue,
fill_color=gold,
align=pymupdf.TEXT_ALIGN_CENTER,
)
# (B) Text (ポップアップコメント) 注釈
text_annot_pos = pymupdf.Point(50, 120)
page.add_text_annot(
text_annot_pos, "これはText注釈の\nポップアップコメントです。", icon="Comment"
)
# (C) Highlight (ハイライト) と Underline (下線) 注釈
# まず、注釈をつけたいテキストをページに書き込む
page.insert_text(pymupdf.Point(50, 200), text_to_highlight, fontsize=11)
page.insert_text(pymupdf.Point(50, 230), text_to_underline, fontsize=11)
# 書き込んだテキストの位置を正確に探し出す
highlight_quads = page.search_for(text_to_highlight, quads=True)
underline_quads = page.search_for(text_to_underline, quads=True)
# 探し出した位置情報を使って注釈を追加
if highlight_quads:
annot = page.add_highlight_annot(highlight_quads[0])
annot.set_colors(stroke=red) # 色を設定
annot.update()
if underline_quads:
annot = page.add_underline_annot(underline_quads[0])
annot.set_colors(stroke=blue) # 色を設定
annot.update()
# --- PDFを保存 ---
doc.save(file_path, garbage=4, deflate=True)
doc.close()
print(f"'{file_path}' を作成しました。")
print("=" * 30)
# --- 2. 作成したPDFを読み込んで注釈情報を表示 ---
print(f"'{file_path}' から注釈を読み込みます。")
doc = pymupdf.open(file_path)
page = doc[0]
print(f"\nページ {page.number + 1} の注釈一覧:")
annots = list(page.annots())
if not annots:
print(" このページに注釈はありません。")
else:
# 注釈の表示順が作成順と異なる場合があるので、y座標でソートする
annots.sort(key=lambda a: a.rect.y0)
for i, annot in enumerate(annots, 1):
print(f"--- 注釈 {i} ---")
print(f" タイプ: {annot.type[1]} ({annot.type[0]})")
print(f" 矩形 (Rect): {annot.rect}")
content = annot.info.get("content", "")
# 改行コード(CR)を\nに置換して表示
content = content.replace(chr(13), "\n")
print(f" 内容 (Content): {content}")
doc.close()
# # 作成したファイルをクリーンアップ
# if os.path.exists(file_path):
# os.remove(file_path)
# print(f"\n'{file_path}' をクリーンアップのため削除しました。")このコードは、注釈のタイプ、位置、内容などの情報を出力します。これにより、PDFレビュープロセスで追加されたコメントを自動で収集したり、特定の注釈に基づいて後続の処理を分岐させたりすることが可能になります。
実践例:PDFレビュープロセスの自動化
[!TIP]
これらの注釈操作機能を組み合わせることで、PDFのレビュープロセスを自動化できます。例えば、特定のキーワードを含む箇所を自動でハイライトし、コメントを追加するスクリプトを作成することで、手作業でのレビュー工数を大幅に削減できます。
import pymupdf
import os
import sys
def automate_pdf_review(input_pdf_path, output_pdf_path, keywords_to_highlight):
"""
PDFを自動レビューし、指定されたキーワードをハイライトしてコメントを追加します。
Args:
input_pdf_path (str): 入力PDFのパス。
output_pdf_path (str): 出力PDFのパス。
keywords_to_highlight (list): ハイライトするキーワードのリスト。
"""
if not os.path.exists(input_pdf_path):
print(
f"エラー: 入力ファイルが見つかりません: {input_pdf_path}", file=sys.stderr
)
return
doc = None # finallyブロックのために初期化
try:
doc = pymupdf.open(input_pdf_path)
for page in doc:
for keyword in keywords_to_highlight:
text_instances = page.search_for(keyword)
for inst in text_instances:
# キーワードをハイライト
highlight = page.add_highlight_annot(inst)
highlight.update()
# コメントを追加
comment_point = pymupdf.Point(inst.top_right)
annot = page.add_text_annot(
comment_point,
f"'{keyword}' が検出されました。",
icon="Note",
)
# set_infoでタイトルを設定
annot.set_info(title="自動レビュー", content=f"'{keyword}' を検出")
annot.update()
doc.save(output_pdf_path, garbage=4, deflate=True)
print(f"PDFレビューが完了しました: {output_pdf_path}")
except Exception as e:
print(f"エラーが発生しました: {e}", file=sys.stderr)
finally:
if doc:
doc.close()
def main():
"""メイン処理"""
# レビュー対象のPDFとキーワードを設定
# create_sample_pdf.pyでサンプルPDFを作成しておくことを想定
input_file = "sample.pdf"
output_file = "reviewed_report.py.pdf"
keywords = ["重要", "要確認", "エラー"]
print(f"入力ファイル: {input_file}")
print(f"出力ファイル: {output_file}")
print(f"検索キーワード: {keywords}")
print("-" * 20)
automate_pdf_review(input_file, output_file, keywords)
if __name__ == "__main__":
main()3. PyMuPDFと他のライブラリとの連携
本シリーズの核となるコンセプトの一つが「複数ライブラリ連携」です。単一のライブラリでは難しい複雑なPDF処理も、それぞれのライブラリの強みを組み合わせることで、効率的かつ高度に実現できます。ここでは、PyMuPDFとpypdf、ReportLabとの連携例を紹介します。
PyMuPDFで抽出したテキスト/画像をReportLabで再利用
PyMuPDFは高速なテキスト・画像抽出に優れています。抽出したこれらのデータをReportLabに渡し、新しいPDFドキュメントのコンテンツとして再利用するワークフローは非常に強力です。
例えば、PyMuPDFで既存のPDFから表データを抽出し、そのデータをReportLabで整形して新しいレポートを生成するシナリオを考えてみましょう。
import pymupdf
import os
from reportlab.lib.pagesizes import letter
from reportlab.lib.units import inch
from reportlab.pdfgen import canvas
from reportlab.pdfbase import pdfmetrics
from reportlab.pdfbase.ttfonts import TTFont
# --- ファイルパスとフォントの設定 ---
# このスクリプトはプロジェクトルートから実行されることを想定
INPUT_PDF = "sample.pdf"
OUTPUT_PDF = "new_report_from_extracted_data.pdf"
FONT_PATH = "ipaexg.ttf"
FONT_NAME = "ipaexg"
# --- 1. PyMuPDFでPDFからテキストを抽出 ---
print(f"'{INPUT_PDF}' からテキストを抽出します...")
doc_extract = pymupdf.open(INPUT_PDF)
# 全ページのテキストを抽出
extracted_text = "".join(page.get_text() for page in doc_extract)
doc_extract.close()
print("テキストの抽出が完了しました。")
# --- 2. 抽出したテキストをReportLabで新しいPDFに描画 ---
print(f"'{OUTPUT_PDF}' を作成します...")
# 日本語フォントを登録
pdfmetrics.registerFont(TTFont(FONT_NAME, FONT_PATH))
# PDFキャンバスを作成
c = canvas.Canvas(OUTPUT_PDF, pagesize=letter)
width, height = letter
# テキストオブジェクトを使用してテキストを描画
textobject = c.beginText()
textobject.setTextOrigin(inch, height - inch)
# タイトルを描画
textobject.setFont(FONT_NAME, 14)
textobject.textLine(f"'{os.path.basename(INPUT_PDF)}' から抽出したテキスト:")
textobject.moveCursor(0, 20) # 見出しとの間隔
# 本文を描画
textobject.setFont(FONT_NAME, 10)
for line in extracted_text.split("\n"):
textobject.textLine(line)
c.drawText(textobject)
c.save()
print(f"日本語フォントでテキストを再描画したPDFを作成しました: {OUTPUT_PDF}")[!著者の経験談]
以前、顧客から提供されたPDF形式の請求書から特定の情報を抽出し、それを元に社内システム用のレポートを自動生成するプロジェクトがありました。PyMuPDFの高速なテキスト抽出能力で必要なデータを効率的に取得し、ReportLabの柔軟なレイアウト機能で、そのデータを視覚的に分かりやすいレポートとして出力することで、手作業によるデータ入力とレポート作成の時間を劇的に削減できました。
pypdfで結合したPDFをPyMuPDFで高速処理
pypdfはPDFの結合や分割といったページ操作に長けています。pypdfで複数のPDFを結合した後、その結合されたPDFをPyMuPDFで開き、高速なテキスト抽出や画像抽出、あるいは高度なレンダリングを行うことで、両者の利点を最大限に引き出すことができます。
import os
import pymupdf
from pypdf import PdfWriter
# --- 定数定義 ---
# このスクリプトはプロジェクトルートから実行されることを想定し、
# ファイルはすべて カレント ディレクトリ内に作成します。
TARGET_DIR = "."
PART1_PDF = os.path.join(TARGET_DIR, "part1.pdf")
PART2_PDF = os.path.join(TARGET_DIR, "part2.pdf")
COMBINED_PDF = os.path.join(TARGET_DIR, "combined.pdf")
def create_dummy_pdf(file_path: str, text: str):
"""簡単なテキストを含むダミーPDFを作成する"""
writer = PdfWriter()
writer.add_blank_page(width=612, height=792) # US Letter size
# PyMuPDFでテキストを抽出できるよう、注釈としてテキストを追加
writer.add_annotation(
page_number=0,
annotation={
"/Type": "/Annot",
"/Subtype": "/FreeText",
"/Rect": [0, 0, 0, 0], # ページ上に表示されないようにする
"/Contents": text,
},
)
with open(file_path, "wb") as f:
writer.write(f)
print(f"ダミーPDFを作成しました: {file_path}")
def main():
"""
pypdfでPDFを結合し、その結果をPyMuPDFで高速に処理する一連の流れを示す。
"""
# --- 1. テスト用の入力PDFを自動生成 ---
print("--- ステップ1: テスト用PDFの作成 ---")
create_dummy_pdf(
PART1_PDF,
"これは1番目のドキュメントのテキストです。PyMuPDFによって読み込まれます。",
)
create_dummy_pdf(
PART2_PDF, "これは2番目のドキュメントの内容です。pypdfで結合されます。"
)
print("-" * 20)
# --- 2. pypdfで複数のPDFを結合 ---
print("--- ステップ2: pypdfでのPDF結合 ---")
merger = PdfWriter()
try:
for pdf_file in [PART1_PDF, PART2_PDF]:
merger.append(pdf_file)
merger.write(COMBINED_PDF)
print(f"pypdfでPDFを結合しました: {COMBINED_PDF}")
except Exception as e:
print(f"PDFの結合中にエラーが発生しました: {e}")
return
finally:
merger.close()
print("-" * 20)
# --- 3. 結合されたPDFをPyMuPDFで開き、高速処理 ---
print("--- ステップ3: PyMuPDFでの結合後PDFの解析 ---")
if not os.path.exists(COMBINED_PDF):
print(f"エラー: 結合されたPDF '{COMBINED_PDF}' が見つかりません。")
return
try:
with pymupdf.open(COMBINED_PDF) as doc_combined:
print(
f"'{COMBINED_PDF}' を PyMuPDF で開きました。ページ数: {doc_combined.page_count}"
)
for page_num, page in enumerate(doc_combined):
print(f"--- ページ {page_num + 1} のテキスト (PyMuPDF) ---")
text = page.get_text().strip()
print(text if text else "(このページにテキストはありません)")
except Exception as e:
print(f"PyMuPDFでの処理中にエラーが発生しました: {e}")
print("-" * 20)
# --- 4. クリーンアップ ---
print("--- ステップ4: クリーンアップ ---")
try:
for file_path in [PART1_PDF, PART2_PDF, COMBINED_PDF]:
if os.path.exists(file_path):
os.remove(file_path)
print(f"ファイルを削除しました: {file_path}")
except Exception as e:
print(f"クリーンアップ中にエラーが発生しました: {e}")
if __name__ == "__main__":
main()複数ライブラリ連携のワークフロー例
複数のライブラリを連携させることで、以下のような複雑なワークフローを構築できます。
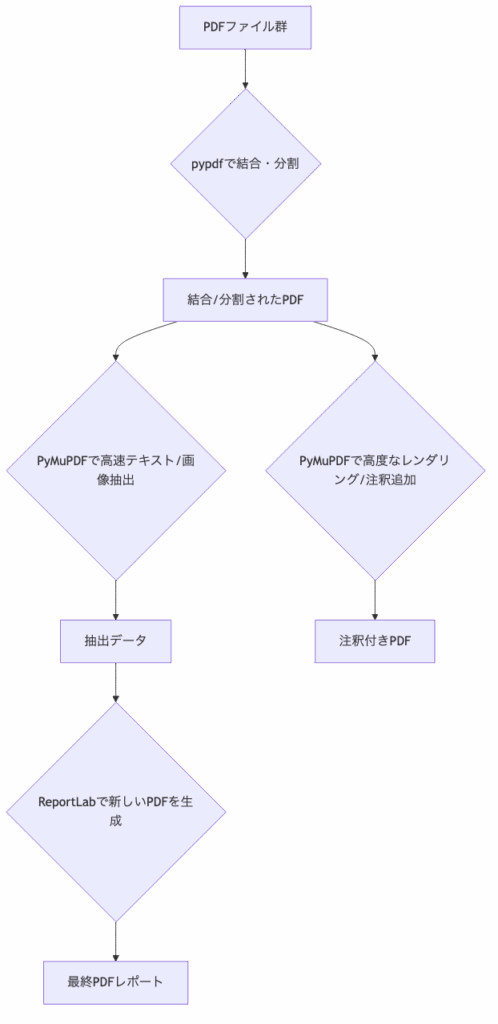
図1: 複数PDFライブラリ連携による高度なワークフロー
この図は、pypdfでPDFの結合や分割を行い、その結果をPyMuPDFで高速に処理(テキスト/画像抽出、レンダリング、注釈追加)し、さらに抽出したデータをReportLabで新しいPDFレポートとして生成するという一連の流れを示しています。
4. まとめ:Python PDF処理の未来と自動化の可能性
本シリーズを通して、私たちはPythonにおける様々なPDFライブラリの機能と、それぞれの得意分野を深く掘り下げてきました。そして本記事では、PyMuPDFの高度なレンダリング機能や注釈操作、さらには複数ライブラリ連携という、PDF自動化の可能性を最大限に引き出すための実践的なテクニックを学びました。
単一のライブラリでは解決が難しかった課題も、PyMuPDF、pypdf、ReportLabといった異なる特性を持つライブラリを適切に組み合わせることで、より柔軟かつ効率的に対応できるようになります。これは、まさにPython PDF処理の「未来」を切り拓くアプローチと言えるでしょう。
今日からできる、はじめの一歩
- 既存のPDF処理タスクを見直す: 現在手作業で行っているPDF関連の業務や、単一ライブラリで限界を感じている自動化タスクはありませんか?それらを複数ライブラリ連携の視点で見直してみましょう。
- 簡単な連携スクリプトを試す: まずは、本記事で紹介したPyMuPDFと
pypdf、ReportLabの簡単な連携コードを実際に動かしてみてください。小さな成功体験が、次のステップへの大きなモチベーションになります。 - 公式ドキュメントを読み込む: 各ライブラリの公式ドキュメントには、さらに多くの機能や応用例が記載されています。興味を持った機能があれば、積極的に深掘りしてみましょう。
この「Python PDFライブラリ徹底活用ガイド」シリーズが、あなたのPDF自動化の旅に役立ったなら幸いです。ぜひ、あなたのプロジェクトでの活用事例や、本記事に関する感想、質問などをコメント欄で教えてください。
また、この記事が役に立ったと感じたら、ぜひチームに共有したり、X(旧Twitter)で感想をポストしてください。あなたのフィードバックが、今後の記事作成の大きな励みになります。
次なるステップとして、このシリーズで得た知識を活かし、さらに複雑なデータ処理やAIとの連携など、Python PDF処理の新たな可能性を探求していきましょう。
5. FAQ
Q1: PyMuPDFと他のライブラリを連携させる際のパフォーマンス上の注意点はありますか?
A1: 複数のライブラリを連携させる場合、PDFドキュメントの読み込みや書き込みが複数回発生する可能性があります。特に大規模なPDFや大量のファイルを処理する場合は、I/Oオーバーヘッドがパフォーマンスに影響を与えることがあります。可能な限り、メモリ上でデータをやり取りする、または中間ファイルを最小限に抑える工夫が必要です。また、各ライブラリの処理速度の特性を理解し、ボトルネックとなる部分にはPyMuPDFのような高速なライブラリを優先的に使用することが重要です。
Q2: PyMuPDFで追加した注釈は、Adobe Acrobatなどの他のPDFビューアで正しく表示されますか?
A2: はい、PyMuPDFで追加された注釈は、PDF標準に準拠しているため、Adobe Acrobat Readerやその他の主要なPDFビューアで問題なく表示されます。ただし、注釈のタイプや設定によっては、ビューア間の互換性にわずかな違いが生じる可能性もゼロではありません。重要なドキュメントで利用する場合は、事前にいくつかのビューアで表示確認を行うことをお勧めします。
Q3: 複数のライブラリを連携させることで、コードが複雑になりませんか?
A3: 複数のライブラリを連携させることで、確かにコードの複雑性は増す可能性があります。しかし、それぞれのライブラリの役割を明確にし、モジュール化されたコードを書くことで、この複雑性を管理することができます。例えば、各ライブラリの処理を関数やクラスとしてカプセル化し、それらを組み合わせてワークフローを構築するアプローチが有効です。また、本シリーズで紹介したように、Mermaid.jsなどを用いてワークフローを図示することで、コードの全体像を把握しやすくなります。
6. 参考資料
- PyMuPDF 公式ドキュメント: https://pymupdf.readthedocs.io/
pypdf公式ドキュメント: https://pypdf.readthedocs.io/- ReportLab 公式ドキュメント: https://docs.reportlab.com/
7. 免責事項
本記事は、PythonにおけるPDFライブラリの利用に関する一般的な情報提供を目的としています。記載されているコード例は、特定の環境やバージョンでの動作を保証するものではありません。実際のプロジェクトに導入する際は、ご自身の責任において十分なテストと検証を行ってください。また、ライブラリのライセンス条項を遵守し、適切に利用してください。