
なぜSpring BatchのChunkサイズとログ出力が重要なのか?
「バッチ処理が遅い」「メモリ不足で落ちる」「エラー時のデバッグが大変」――Spring Batchを使った開発で、こんな課題に直面していませんか?
本記事は、Spring Batchを使い始めたばかりのエンジニアの皆さんが、これらの悩みを解決し、安定・高速なバッチ処理を開発できるようになるためのガイドです。
Spring Batchの心臓部とも言えるChunk処理の「コミットインターバル(Chunkサイズ)」の最適な設定方法と、処理の進行状況を把握するための「ログ出力」について、具体的なコード例を交えながら徹底解説します。
この記事を読めば、あなたのSpring Batchアプリケーションは、より効率的で信頼性の高いものへと進化するでしょう。
目次
- 1. Spring BatchのChunk処理とは?基本概念を理解しよう
- 1-1. Read-Process-Writeサイクル:Chunk処理の仕組み
- 1-2. Chunk処理のイメージ図で全体像を掴む
- 2. コミットインターバル(Chunkサイズ)の具体的な設定方法と最適化
- 2-1. Chunkサイズを
application.propertiesに定義 - 2-2. コミットインターバル(Chunkサイズ)を決定する際の考慮事項と最適化のポイント
- 2-1. Chunkサイズを
- 3. チャンク処理の進行状況を可視化!
ChunkListenerを使ったログ出力- 3-1.
ChunkListenerを使ったログ出力の具体的な方法
- 3-1.
- まとめ:Spring BatchのChunk処理をマスターして、安定・高速なバッチ開発へ!
対象読者
- Spring Batchを使い始めたばかりのJavaエンジニア
- バッチ処理のパフォーマンス最適化や安定稼働に関心のある開発者
- Spring BatchのChunk処理の概念と実践的な設定方法を学びたい方
- ログ出力によるバッチ処理の可視化・デバッグ方法を知りたい方
1. Spring BatchのChunk処理とは?基本概念を理解しよう
Spring Batchは、世界中の多くの企業で基幹バッチ処理に利用されており、DockerやKubernetesといったコンテナ技術と組み合わせることで、クラウド環境でのスケーラブルなバッチ処理も容易に実現できます。
本記事の内容は、特定の環境に依存せず、グローバルな開発現場で役立つ普遍的な知識を提供します。
1-1. Read-Process-Writeサイクル:Chunk処理の仕組み
Spring Batchは、その最も一般的な実装において「Chunk指向」の処理スタイルを使用しています。
チャンク指向処理とは、データを1つずつ読み込み、トランザクション境界内で書き出される「Chunk」を作成することを指します。
具体的には、データを「読み込み(Read)」「処理(Process)」「書き込み(Write)」という一連のチャンク(塊)で処理するモデルです。
読み込まれたアイテムの数がコミット間隔に達すると、ItemWriterによってチャンク全体が書き出され、その後トランザクションがコミットされます。
1-2. Chunk処理のイメージ図で全体像を掴む
Chunk指向処理のライフサイクル:
この一連の流れをシーケンス図で表すと以下のようになります。
図:Chunk処理のイメージ
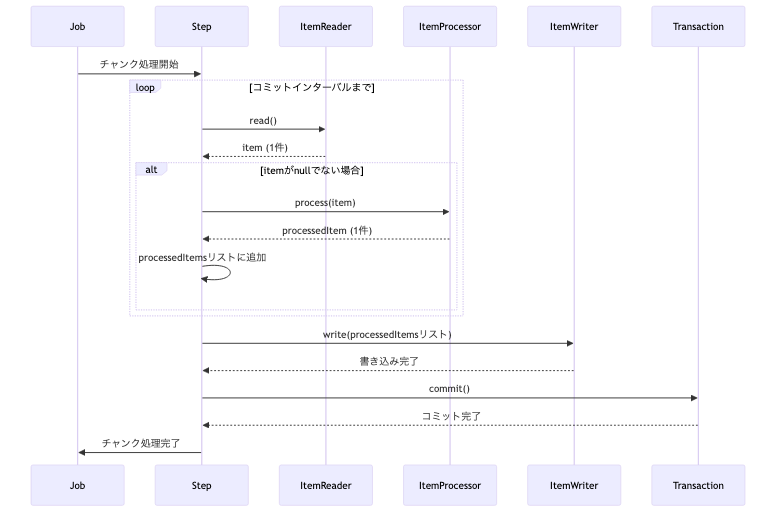
上記のシーケンス図は、Chunk指向処理のライフサイクルを視覚的に示しています。JobからStepが開始され、StepがItemReader、ItemProcessor、ItemWriterをオーケストレーションします。
このサイクルを効率的に運用するためには、次項で解説する「チャンクサイズ」や「トランザクション境界」の適切な設定が非常に重要になります。
Spring BatchのChunk処理の詳細については、以下の記事で詳細に解説していますので、是非ご覧ください。
2. コミットインターバル(Chunkサイズ)の具体的な設定方法と最適化
このセクションでは、Spring Batchにおけるコミットインターバル(Chunkサイズ)の具体的な設定方法と、その決定に際して考慮すべき事項について詳しく解説します。
Chunkサイズはバッチ処理のパフォーマンスに大きく影響するため、適切に設定することが重要です。
Spring Batchのサンプルコードについては、以下の記事で詳細に解説していますので、是非ご覧ください。
2-1. Chunkサイズをapplication.propertiesに定義
チャンクサイズは、application.propertiesに定義し、アプリケーション起動時に静的に設定する方法が一般的です。
ジョブ実行時のパラメータでチャンクサイズを動的に変更するアプローチは、ScopeNotActiveExceptionを引き起こす原因となるため、避けるべきとされています。
これは、Spring BatchのStepがジョブの「設計図」であり、その構成はジョブ構築時に確定しているべきという設計思想に合致しないためです。
単一のステップにチャンクサイズを設定する
application.propertiesにチャンクサイズのデフォルト値を定義し、BatchConfig.javaのStep Bean定義で、@Valueアノテーションを使ってこの値をインジェクトします。
application.properties
# デフォルトのコミットインターバル
batch.commit-interval.default=10BatchConfig.java
- UserOperationは、ユーザー操作を表すドメインオブジェクトと仮定します。
- このStepでは、UserOperationを読み込み、処理し、書き出すことを想定しています。
@Bean
public Step processUserOperationStep(
// @Valueアノテーションは、application.propertiesから値をインジェクトするために使用します。
// `${...}`はプロパティのキーを示し、`:10`はプロパティが見つからない場合のデフォルト値です。
// ここでは、Spring Expression Language (SpEL) を使ってプロパティ値を解決しています。
@Value("${batch.commit-interval.default:10}") int commitInterval
) {
return new StepBuilder("processUserOperationStep", jobRepository)
// <入力型, 出力型>chunk(コミット間隔, トランザクション管理)
// ここで指定した件数ごとに、トランザクションがコミットされます。
.<UserOperation, UserOperation>chunk(
commitInterval,
transactionManager
)
// ... reader, processor, writer (実際の処理はここに定義されます)
.build();
}応用例:ステップ毎に異なるチャンクサイズを設定する
一つのジョブに複数のステップがあり、それぞれ異なるチャンクサイズを設定したい場合は、application.propertiesにステップ毎のプロパティを定義します。
先ほどのコードに読み込んだユーザー総数をSummaryとして記録する機能を追加します。
最初に、application.propertiesにSummaryのインターバルを追加します。
application.properties
- この設定は、
application.propertiesで各ステップに固有のチャンクサイズを定義する方法を示しています。 userOperationStepには10、summaryStepには5というコミットインターバルが割り当てられます。
# userOperationStep用のコミットインターバル
batch.commit-interval.user-operation=10
# summaryStep用のコミットインターバル
batch.commit-interval.summary=5次に、ユーザー総数(Summary)を格納するEntityとRepositoryを実装します。
Summary.java(抜粋)
Summaryクラスは、ユーザー総数などの集計結果をデータベースに保存するためのエンティティです。summaryNameが集計のカテゴリ、summaryValueが集計された値、createdAtがレコード作成日時を表します。
@Entity
@Table(name = "summaries")
@Data
public class Summary {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
private String summaryName; // 集計の種類(例: "Total Users")
private long summaryValue; // 集計値
private LocalDateTime createdAt; // 作成日時SummaryRepository.java(抜粋)
SummaryRepositoryは、Summaryエンティティに対するデータアクセス操作(保存、検索など)を提供するSpring Data JPAのリポジトリインターフェースです。
@Repository
public interface SummaryRepository extends JpaRepository<Summary, Long> {
}最後に、ユーザー数を集計するsummaryReader、summaryProcessor、summaryWriterを作成して、それらの処理をsummaryStepとして組み立てます。
BatchConfig.java(抜粋)
- UserOperationはユーザー操作、Summaryは集計結果を表すドメインオブジェクトと仮定します。
@Configuration
public class BatchConfig {
private final JobRepository jobRepository;
private final PlatformTransactionManager transactionManager;
private final UserRepository userRepository;
private final SummaryRepository summaryRepository; // SummaryRepositoryをインジェクション
public BatchConfig(
JobRepository jobRepository,
PlatformTransactionManager transactionManager,
UserRepository userRepository,
SummaryRepository summaryRepository // コンストラクタに追加
) {
this.jobRepository = jobRepository;
this.transactionManager = transactionManager;
this.userRepository = userRepository;
this.summaryRepository = summaryRepository;
}
@Bean
public FlatFileItemReader<UserOperation> userOperationReader() {
return new FlatFileItemReaderBuilder<UserOperation>()
.name("userOperationReader")
.resource(new ClassPathResource("input/input.csv"))
.delimited()
.names("operation", "id", "name", "email", "status")
.fieldSetMapper(
new BeanWrapperFieldSetMapper<>() {
{
setTargetType(UserOperation.class);
}
}
)
.build();
}
@Bean
public UserOperationProcessor userOperationProcessor() {
return new UserOperationProcessor();
}
@Bean
public UserOperationWriter userOperationWriter() {
return new UserOperationWriter(userRepository);
}
// --- userOperationStepの定義 ---
@Bean
public Step userOperationStep(
// application.propertiesからステップ固有の値を読み込む
@Value("${batch.commit-interval.user-operation:10}") int commitInterval
) {
return new StepBuilder("userOperationStep", jobRepository)
.<UserOperation, UserOperation>chunk(
commitInterval,
transactionManager
)
.reader(userOperationReader())
.processor(userOperationProcessor())
.writer(userOperationWriter())
.listener(new LoggingChunkListener())
.build();
}
// --- summaryStepの定義 ---
@Bean
public ItemReader<Long> summaryReader() {
// `summaryReader`は、`userRepository.count()`で取得した全ユーザー数を単一の`Long`型アイテムとして読み込む`ItemReader`です。
// `IteratorItemReader`を使用することで、コレクション内の要素を順次読み込みます。
return new IteratorItemReader<>(
Collections.singletonList(userRepository.count())
);
}
@Bean
public ItemProcessor<Long, Summary> summaryProcessor() {
// `summaryProcessor`は、`summaryReader`から渡されたユーザー総数(`Long`)を受け取り、それを`Summary`オブジェクトに変換します。
// 集計名、集計値、作成日時を設定して返します。
return count -> {
Summary summary = new Summary();
summary.setSummaryName("Total Users"); // 集計名を"Total Users"に設定
summary.setSummaryValue(count); // 読み込んだユーザー総数を集計値として設定
summary.setCreatedAt(LocalDateTime.now()); // 現在時刻を作成日時として設定
return summary;
};
}
@Bean
public ItemWriter<Summary> summaryWriter() {
// `summaryWriter`は、`summaryProcessor`から処理された`Summary`オブジェクトのリストを受け取り、
// `summaryRepository.saveAll()`メソッドを使ってデータベースに一括で永続化します。
return summaries -> summaryRepository.saveAll(summaries); // 複数のSummaryオブジェクトを一括でDBに保存
}
@Bean
public Step summaryStep(
// application.propertiesからステップ固有の値を読み込む
@Value("${batch.commit-interval.summary:5}") int commitInterval // summaryStep専用のコミットインターバルをインジェクト
) {
// `summaryStep`は、ユーザー総数集計の`Step`を定義します。
// `@Value`アノテーションにより`application.properties`から`summaryStep`専用の`commitInterval`を読み込み、
// その値でチャンク処理を行います。
// `summaryReader`、`summaryProcessor`、`summaryWriter`を連携させ、`LoggingChunkListener`を登録しています。
return new StepBuilder("summaryStep", jobRepository)
.<Long, Summary>chunk(commitInterval, transactionManager) // 読み込んだcommitIntervalでチャンク処理を設定
.reader(summaryReader())
.processor(summaryProcessor())
.writer(summaryWriter())
.listener(new LoggingChunkListener()) // LoggingChunkListenerを登録
.build();
}
// --- Jobの定義 ---
@Bean
public Job userOperationJob(Step userOperationStep, Step summaryStep) {
// `userOperationJob`は、`userOperationStep`と`summaryStep`という2つのステップを順次実行する`Job`を定義します。
// `start()`で最初のステップを指定し、`next()`で次のステップを連結することで、複数のステップからなるバッチ処理フローを構築します。
return new JobBuilder("userOperationJob", jobRepository)
.start(userOperationStep) // 最初にuserOperationStepを実行
.next(summaryStep) // userOperationStepの完了後にsummaryStepを実行
.build();
}
}このように、各StepのBean定義メソッドで、それぞれに対応するプロパティを@Valueで読み込むことで、ステップの特性に応じたチャンクサイズを柔軟に管理できます。
2-2. コミットインターバル(Chunkサイズ)を決定する際の考慮事項と最適化のポイント
最適化のポイント:
- メモリ使用量:
- Chunkサイズが大きすぎると、コミットされるまでの間に処理対象のアイテムがメモリ上に保持され続けるため、OutOfMemoryErrorの原因となる可能性があります。
- システムのメモリ容量と処理対象のアイテムサイズを考慮して、適切なサイズを設定してください。
- トランザクションのオーバーヘッド:
- Chunkサイズが小さすぎると、コミット処理が頻繁に発生し、トランザクションの開始・終了によるオーバーヘッドが増大し、パフォーマンスが低下する可能性があります。
- データソースの特性:
- データベースへの書き込みが多い場合、Chunkサイズを大きくすることで、バッチ更新の効率が向上し、I/O回数を減らすことができます。
- 処理の複雑さ:
- ItemProcessorで複雑な処理を行う場合、Chunkサイズを小さめに設定することで、各Chunkの処理時間を短縮し、エラー発生時の再試行範囲を限定できます。
- 再起動可能性:
- エラー発生時の再起動を考慮すると、Chunkサイズはあまり大きくしすぎない方が良い場合があります。再起動時にスキップされるアイテムの数を最小限に抑えることができます。
3. チャンク処理の進行状況を可視化!ChunkListenerを使ったログ出力
バッチ処理は長時間にわたることが多く、その進行状況を把握することは非常に重要です。
「今、どこまで処理が進んでいるのか?」「エラーは発生していないか?」といった疑問に答えるために、ログ出力は欠かせません。
このセクションでは、Spring Batchのチャンク処理において、各チャンクがコミットされるタイミングでログを出力する方法について解説します。
これにより、バッチ処理の進行状況や、エラー発生時のデバッグが容易になります。
3-1. ChunkListenerを使ったログ出力の具体的な方法
各チャンクがコミットされるタイミングでログを出力するには、Spring Batchが標準で提供する ChunkListenerを使用する方法が最も効果的です。
ChunkListenerは、Spring BatchのChunk処理のライフサイクル(開始前、コミット後、エラー後)にフックして処理を実行できるインターフェースです。
特にafterChunkメソッドは、チャンクのトランザクションが正常にコミットされた後に呼び出されるため、処理が確実に完了したことを記録するのに最適なタイミングとなります。
下記の図は、Spring BatchのChunk処理のライフサイクルと、ChunkListenerの各フックポイント(beforeChunk、afterChunk、afterChunkError)がどのタイミングで呼び出されるかを示しています。
図:Chunk処理の全体像と、リスナーによる介入ポイント

実装例
まず、ChunkListenerインターフェースを実装したリスナークラスを作成します。
LoggingChunkListener.java
- ChunkListenerインターフェースを実装することで、チャンク処理の様々なタイミング(開始前、コミット後、エラー後)に処理を割り込ませることができます。
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.springframework.batch.core.ChunkListener;
import org.springframework.batch.core.scope.context.ChunkContext;
public class LoggingChunkListener implements ChunkListener {
private static final Logger LOGGER = LoggerFactory.getLogger(LoggingChunkListener.class);
// 各チャンク処理の開始直前に呼び出されます。
@Override
public void beforeChunk(ChunkContext context) {
LOGGER.info("チャンク処理を開始します。");
}
// 各チャンク処理が正常に完了し、トランザクションがコミットされた後に呼び出されます。
@Override
public void afterChunk(ChunkContext context) {
// StepExecutionから、これまでに書き込まれたアイテムの総数を取得します。
long count = context.getStepContext().getStepExecution().getWriteCount();
LOGGER.info("チャンクが正常にコミットされました。処理済みアイテム数: {}", count);
}
// チャンク処理中にエラーが発生し、トランザクションがロールバックされた後に呼び出されます。
@Override
public void afterChunkError(ChunkContext context) {
LOGGER.error("チャンク処理中にエラーが発生しました。");
}
}次に、BatchConfig.javaで、このリスナーをStepに登録します。
BatchConfig.java
@Bean
public Step processUserOperationStep(...) {
return new StepBuilder(...)
// ... (ItemReader, ItemProcessor, ItemWriterなどの設定)
// .listener()メソッドで、作成したChunkListenerのインスタンスをStepに登録します。
// これにより、チャンク処理のライフサイクルイベント時にLoggingChunkListenerのメソッドが呼び出されます。
.listener(new LoggingChunkListener())
.build();
}参考情報
- Spring Batch Reference Documentation (Chunk-oriented Processing):
ChunkListenerのインターフェースとライフサイクルについて解説されています。
まとめ:Spring BatchのChunk処理をマスターして、安定・高速なバッチ開発へ!
本記事では、Spring BatchのChunk処理におけるコミットインターバル(Chunkサイズ)の最適な設定方法と、ChunkListenerを活用したログ出力について解説しました。
- Chunkサイズ:
application.propertiesで静的に設定し、メモリ使用量、トランザクションオーバーヘッド、データソース特性、処理の複雑さ、再起動可能性を考慮して決定することが重要です。 - また、
@StepScopeをStepBean自体に適用することは避けるべきです。 - ログ出力:
ChunkListenerを使用することで、各チャンクのコミットタイミングで処理状況を正確に把握し、デバッグや運用を効率化できます。
これらの知識を活かすことで、皆さんのSpring Batchアプリケーションは、より効率的で信頼性の高いものへと進化するでしょう。
ぜひ、この記事で学んだことを活かして、ご自身のSpring BatchアプリケーションのChunkサイズを調整し、ChunkListenerを導入してみてください。
Spring Batchに関する疑問や、あなたのプロジェクトでの経験をぜひコメントで共有してください!
免責事項
本記事は、Spring BatchのChunk処理とログ出力に関する一般的な情報提供を目的としています。
記載されている情報やコード例は、特定の環境や要件に完全に合致することを保証するものではありません。
実際のシステムに適用する際は、ご自身の責任において十分な検証とテストを行ってください。
本記事の内容によって生じたいかなる損害についても、筆者および公開元は一切の責任を負いません。